Rodei 3 sessões do Claude Code em paralelo por 8 horas. Elas se sobrescreveram 2 vezes. R$ 280 em retrabalho.
Eu tinha três ideias em paralelo e três terminais abertos. A conta parecia óbvia: abrir três sessões do Claude Code, uma por worktree, deixar cada uma trabalhar em uma branch independente, e ganhar uns 3x de throughput na tarde. A documentação oficial recomenda exatamente isso. O desktop app cria worktree automaticamente para cada nova sessão. É apresentado como o padrão seguro.
Oito horas depois, eu tinha dois arquivos de memória corrompidos, um arquivo de Skill com um parágrafo que eu nunca escrevi, e uma fatura de aproximadamente R$ 280 de tokens (cerca de US$ 47, com o dólar em 5,95 no fechamento de 2026-05-27) refazendo trabalho que já existia em outra worktree. A configuração era segura no papel. O estado compartilhado não era.
Esse post é o log das 8 horas. O que eu configurei, quando as duas colisões aconteceram, o que estava sendo sobrescrito de fato, e os três padrões pequenos que uso agora para impedir que sessões paralelas se devorem.
A configuração que parecia segura
Três sessões do Claude Code, cada uma em uma worktree separada do mesmo repositório. Três branches: feat/voice-buffer, fix/og-emit, feat/citation-tracker. Nenhuma das branches tocava nos mesmos arquivos-fonte. Eu checei duas vezes antes de começar.
# Terminal A
git worktree add ../wt-voice-buffer feat/voice-buffer
cd ../wt-voice-buffer && claude
# Terminal B
git worktree add ../wt-og-emit fix/og-emit
cd ../wt-og-emit && claude
# Terminal C
git worktree add ../wt-citations feat/citation-tracker
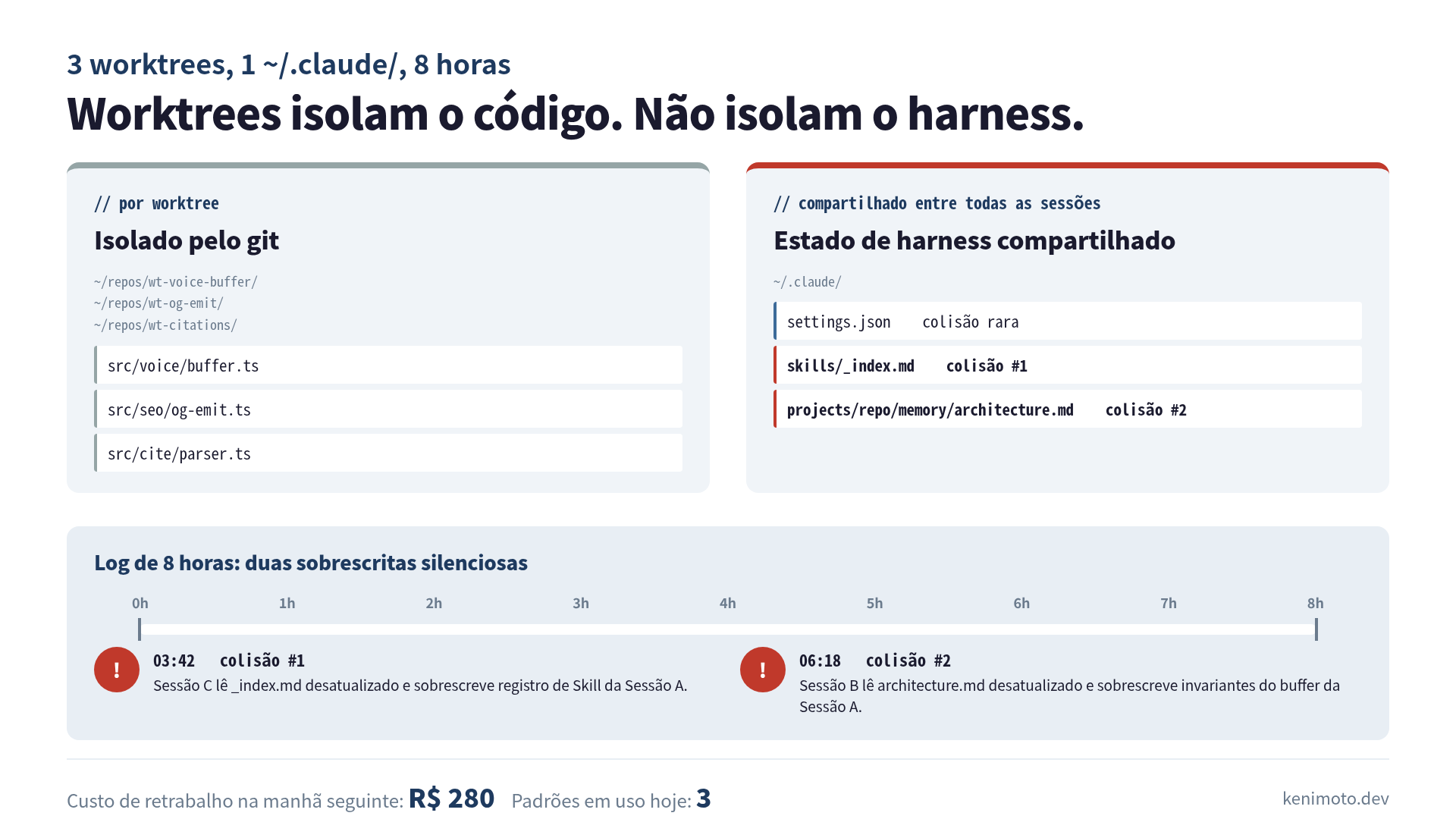
cd ../wt-citations && claudeCada sessão lia o mesmo contexto de sistema: o CLAUDE.md do repositório, o ~/.claude/CLAUDE.md de usuário, o ~/.claude/skills/, e o diretório ~/.claude/projects/<repo>/memory/. As worktrees são isoladas na camada de git. Todo o resto fica compartilhado.
Percebi a implicação só na hora 8, com um arquivo de memória corrompido aberto na tela. Worktrees isolam o código-fonte. Não isolam o cérebro do Claude.
Colisão 1: hora 3, o arquivo de Skill
A primeira coisa a quebrar foi um arquivo de Skill no qual eu não tinha encostado o dia inteiro.
A sessão A estava trabalhando no fix do voice buffer e em algum momento se perguntou: “tem alguma Skill para buffers WebRTC streaming?”. Não tinha. Escreveu uma nova em ~/.claude/skills/voice-buffer/SKILL.md e seguiu trabalhando. Na mesma janela de uns 8 minutos, a sessão C estava montando o citation tracker e se perguntou: “tem alguma Skill para parser de atribuições de fonte?”. Não tinha. Escreveu uma em ~/.claude/skills/citation-source/SKILL.md.
Até aí nenhuma colisão. Arquivos diferentes, tópicos diferentes. A documentação oficial não me deu motivo para suspeitar.
A colisão veio de um terceiro arquivo: ~/.claude/skills/_index.md, que as duas sessões decidiram atualizar ao registrar a Skill nova. A sessão A escreveu primeiro. A sessão C, lendo o arquivo 30 segundos depois, viu a versão anterior à escrita da A, anexou a própria Skill e salvou. O registro da Skill voice-buffer desapareceu do índice. A sessão A não tinha como saber, porque já tinha seguido para a próxima tarefa.
Eu só percebi na hora 5 quando perguntei para a sessão B (que estava silenciosa no fix do OG): “o índice de Skills já inclui voice-buffer?”. Ela respondeu que não. Conferi. Estava certa. O arquivo de Skill que a A escreveu estava em disco, mas o índice que apontava para ele tinha sido sobrescrito.
Isso é a cara de estado compartilhado sem lock. Dois escritores, last-write-wins, sem aviso, sem merge.
Colisão 2: hora 6, o arquivo de memória
A segunda colisão foi pior, porque comeu trabalho que eu queria manter.
Eu uso ~/.claude/projects/<repo>/memory/ para guardar pequenas notas persistentes que o agente deve lembrar entre sessões: um architecture.md com o mapa dos componentes, um feedback.md com preferências de estilo, um project.md com prioridades atuais. Os três são escritos pelo próprio Claude, eventualmente, quando o usuário diz “lembre disso” ou quando o agente decide por conta própria que algo vale guardar.
Na hora 6
, a sessão A terminou o trabalho no voice buffer e se perguntou: “vale a pena salvar o que aprendi sobre os invariantes do buffer de áudio?”. Leuarchitecture.md, adicionou uma seção, salvou. Na hora 6, a sessão B terminou o fix do OG e se perguntou: “vale a pena registrar o bug de duplo og como gotcha conhecido?”. Leu architecture.md (a versão pré-A, ainda em cache no contexto dela), adicionou a própria seção, salvou.
As notas do voice buffer da A sumiram. Oito minutos de invariantes cuidadosos, fora, substituídos por um parágrafo sobre emissão de meta tag que estava correto mas era de outro assunto.
Só peguei isso porque, na manhã seguinte, fui dar grep em “buffer invariant” e não encontrei nada. Se eu não tivesse procurado, as notas simplesmente não existiriam em nenhuma sessão futura do Claude Code. O agente nunca saberia que devia perguntar. Não tem log de erro para “arquivo de memória sobrescrito silenciosamente por processo irmão”.
O que estava de fato quebrado
Worktrees resolvem o problema de filesystem. Duas sessões escrevendo no mesmo src/voice/buffer.ts gerariam um conflito de git, que é barulhento e recuperável. Duas sessões escrevendo no mesmo ~/.claude/skills/_index.md geram um overwrite silencioso, que é mudo e não.
Concretamente, a premissa quebrada era essa. O guia oficial diz que “edições em uma sessão não tocam em arquivos de outra”, e isso é verdade na camada de worktree. Não é verdade na camada de harness, porque o harness (memória, skills, hooks, settings) mora um diretório acima da worktree, em ~/.claude/, onde cada sessão paralela escreve livremente sem coordenação.
Três classes de arquivo entram em risco, em ordem crescente de quanto vão doer:
- Arquivos de configuração (
~/.claude/settings.json). Colisão rara porque o agente raramente escreve aqui. Mas quando escreve (uma Skill pede permissão nova, por exemplo), é last-write-wins. - Arquivos de Skills (
~/.claude/skills/). Frequência média. O ponto real de ignição são os índices e catálogos compartilhados, não os arquivos SKILL.md individuais. - Arquivos de memória (
~/.claude/projects/<repo>/memory/). O mais dolorido. O agente escreve aqui exatamente no momento em que acabou de aprender algo que considera valioso, ou seja, exatamente o trabalho que você não quer perder.
O padrão de worktree paralela da Anthropic foi pensado para código. O harness foi pensado para uma sessão de cada vez. Rodar os dois ao mesmo tempo é bug do usuário.
A aula de R$ 280
O custo em dinheiro foi o retrabalho. Depois da colisão do arquivo de memória, a sessão A não tinha registro dos invariantes do voice buffer que tinha acabado de derivar. Quando comecei uma sessão nova na manhã seguinte e pedi para estender o buffer, ela rederivou os mesmos invariantes do zero, do mesmo jeito, em uns 40 minutos de tokens queimados. Olhei o dashboard: cerca de US$ 47 em Sonnet 4.6, que dá uns R$ 280 na cotação do fechamento de 2026-05-27 (Banco Central com dólar em 5,95). E mais uma manhã ligeiramente azeda.
Eu também já tinha pago pela derivação original, claro. Então, em rigor, o trabalho não foi “perdido”, foi “pago duas vezes”. A segunda fatura era a evitável. A Lei de Brooks tem uma nota de rodapé que ninguém cita: “e seus processos concorrentes vão sobrescrever as notas uns dos outros, então você vai pagar parte do trabalho duas vezes”. No câmbio de R$ 280, dá para sentir.
Os 3 padrões que uso agora
Depois do dia da colisão, mudei três coisas. Cada uma é pequena. Nenhuma exigiu que a Anthropic mandasse algo novo.
Padrão 1: namespaces de memória por sessão. Em vez de um ~/.claude/projects/<repo>/memory/ compartilhado, cada sessão paralela escreve dentro de ~/.claude/projects/<repo>/memory/<branch-name>/. Coloco isso num CLAUDE.md por worktree, que aponta o agente para o subdiretório dele. No fim da sessão, faço merge do subdiretório de volta para o memory/ principal na mão ou com um script pequeno. Conflitos aparecem como nomes de arquivo duplicados, que é barulhento e recuperável.
<!-- CLAUDE.md por worktree -->
## Local de escrita de memória
Escreva todos os arquivos de memória em
`~/.claude/projects/repo/memory/feat-voice-buffer/`.
Não escreva direto em `~/.claude/projects/repo/memory/`.Padrão 2: write lock nos índices compartilhados. Para arquivos que não dá para isolar por namespace (o índice de Skills, settings.json), uso um lock estilo flock em volta de cada escrita do agente. O agente escreve via um wrapper de shell que pega lock exclusivo em ~/.claude/locks/skills-index.lock antes de tocar no arquivo. Last-write ainda ganha, mas as escritas ficam serializadas e o read pré-escrita do agente vê estado consistente. O wrapper tem uns 20 linhas de shell.
#!/usr/bin/env bash
# ~/.claude/bin/locked-write.sh
target="$1"
lockfile="$HOME/.claude/locks/$(basename "$target").lock"
mkdir -p "$(dirname "$lockfile")"
exec 9>"$lockfile"
flock 9
cat > "$target"Padrão 3: coordenação via .claude/sessions/. Cada sessão em execução escreve um arquivo de heartbeat em ~/.claude/sessions/<pid>.json com branch, horário de início, e os arquivos que ela espera tocar na camada de harness. Antes de escrever em um índice compartilhado ou arquivo de memória, a sessão dá grep no diretório sessions/ atrás de reivindicações de processos irmãos no mesmo caminho. Se acha alguma, espera ou pula. É o mais pesado dos três e o que eu menos uso, porque os Padrões 1 e 2 pegam a maioria das colisões reais.
Se você já usou sub-agentes do Claude Code para revisão paralela, reconhece o formato. O problema não é o modelo. É a camada de integração que o usuário não percebeu que estava ali. Sub-agentes colidem em opiniões dentro de uma sessão; sessões paralelas colidem em estado entre harnesses.
No que eu de fato acredito agora
Sessões paralelas do Claude Code não são de graça, do mesmo jeito que code review multi-agente não é, do mesmo jeito que deixar um agente rodando 24 horas não é. O custo muda de lugar, mas não vai a zero. Em sessões paralelas, o custo aparece como overwrite silencioso no seu diretório de harness, 8 horas depois de começar, em um arquivo em que você nem pensou quando abriu o segundo terminal.
O enquadramento do guia oficial está correto na camada de código-fonte: “edições em uma sessão não tocam arquivos de outra”. Só para um diretório antes. As edições dentro de ~/.claude/ ficam felicíssimas em tocar umas nas outras, e vão tocar, no cronograma do last-write-wins, sem log de erro para dar grep depois.
Se você levar uma coisa só desse post: ao abrir a segunda sessão do Claude Code na segunda worktree, gaste 10 segundos para decidir se as duas sessões compartilham Skills, memória ou settings, e se você se incomoda com a possibilidade de uma comer silenciosamente as escritas da outra. Se se incomoda, coloca o Padrão 1 hoje e o Padrão 2 no primeiro dia em que você bater numa colisão de verdade. O Padrão 3 pode esperar até você se ver rodando 5 em paralelo, que é o ponto em que a documentação oficial sugere com delicadeza que você pare.
Continuo rodando sessões em paralelo. Só parei de fingir que o limite da worktree era o limite todo.
Os 3 padrões (e o capítulo de Skills/memória/settings que explica por que eles colidem) estão em Practical Claude Code. O capítulo de Plan Mode é o que mais releio antes de abrir a segunda sessão.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?