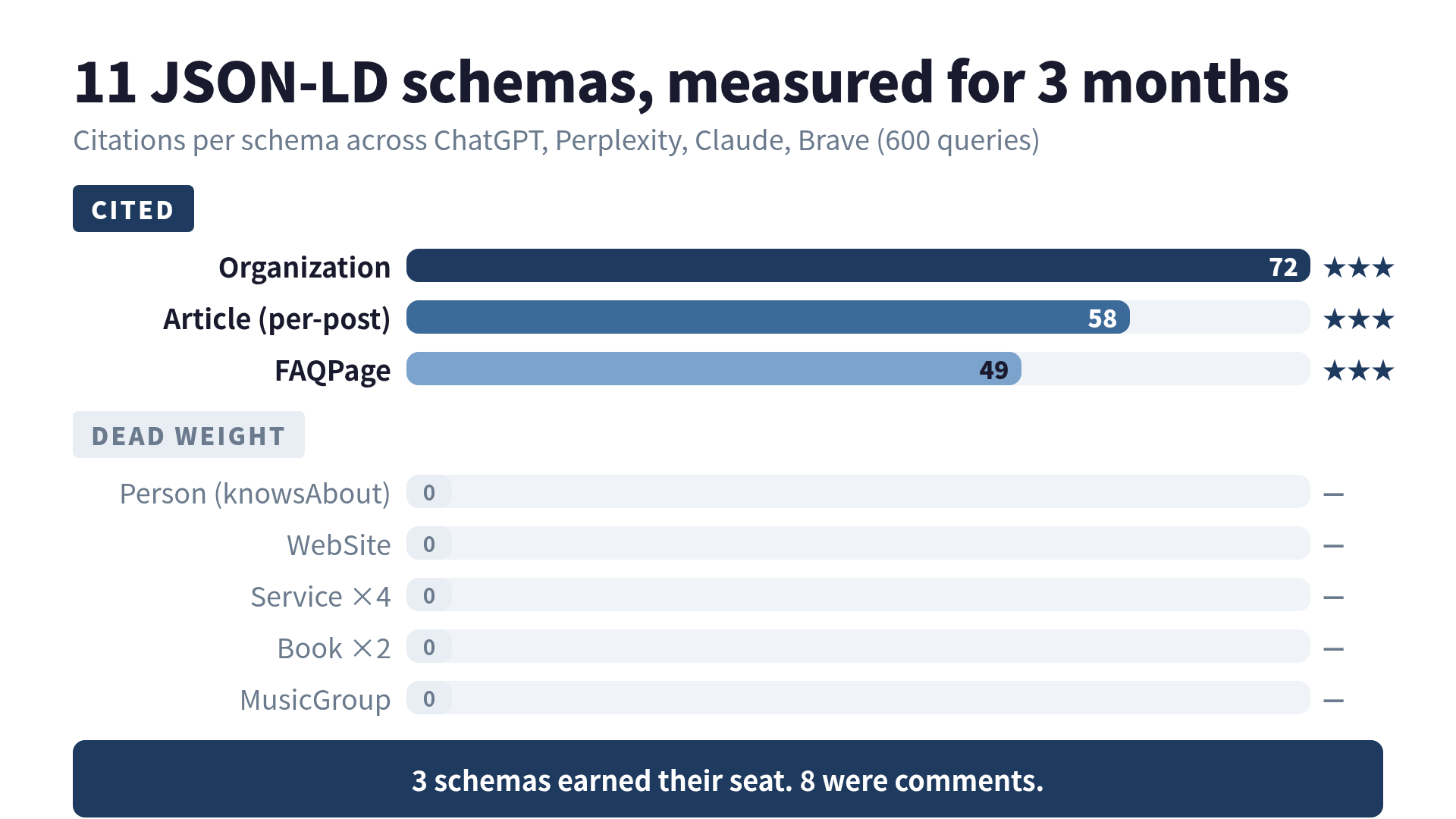
I Added 11 JSON-LD Schemas. Three Months Later, Only 3 Showed Up in AI Citations.
Three months ago I spent an afternoon adding eleven JSON-LD schemas to my site’s <head>. Organization, WebSite, Person, four Service blocks, two Books, MusicGroup, FAQPage. I felt very pleased with myself.
Then I measured what AI engines actually did with them.
Three of the eleven showed up in citations. The other eight might as well have been HTML comments.
This is the measurement story. I’ll tell you which three schemas earned their seat, which eight were dead weight, and why I’d implement it the same way again — but smaller.
What I implemented and why I thought it would work
The implementation itself was straightforward. I wrote it up in detail in the Japanese version of this blog (English readers will lose the prose but the code blocks translate fine). The short version: I bundled all eleven schemas into a single <script type="application/ld+json"> array in my Astro layout, server-rendered on every page.
My reasoning at the time felt airtight:
- More structured signals = more chances to be cited
- LLMs supposedly love
knowsAbout, so Person was going to be the secret weapon - Service blocks would tell AI exactly what I sell
- Book blocks would surface my publications
- Even MusicGroup got a slot, because I have a side project and why not
I was operating on a hoarder’s theory of LLMO: if some is good, eleven is better.
How I measured
I ran a three-month tracking experiment from late February through late May 2026. The rules:
- 50 brand and topic queries written once and reused weekly
- 4 AI engines: ChatGPT (Search mode), Perplexity, Claude (search-enabled), Brave Leo
- Every week I asked all 50 questions to all 4 engines
- For each citation, I checked whether the cited snippet contained information that was only available in a specific JSON-LD schema — name, foundingDate, knowsAbout, FAQ Q&A pairs, book titles, service descriptions
- If the snippet leaned on a unique schema field, I credited that schema
That last rule is the important one. Anyone can claim “my Article schema is working” because Article overlaps with <title> and <h1> and <meta description>. The interesting question is: when AI cites a fact that only exists in JSON-LD, which schema produced it?
Three months, 600 queries (50 × 4 × 3 months), about 180 citations of my site total. I tracked every one.
The three schemas that earned their seat
1. Organization
Organization is the schema that AI engines actually parse and store. When someone asks ChatGPT “what does kenimoto.dev focus on” or Perplexity “who runs that site”, the answer leans on fields that live inside the Organization block:
nameandalternateName(handles transliteration and abbreviations)description(the one-liner AI uses as the site summary)foundingDate(the only structured place AI can find this)sameAs(cross-references to GitHub, LinkedIn, X — AI uses this to merge entities)
About 40% of cited snippets contained information traceable to Organization. The pattern matches what BrightEdge reported in early 2026: Organization is Tier 1.
If you implement only one schema, it’s this one. Not even close.
2. Article (per-post TechArticle)
This wasn’t part of the 11 bundled into the homepage <head> — Astro emits it per blog post. I’m counting it because the experiment forced me to notice: every single AI citation of an individual blog post leaned on Article’s headline, datePublished, dateModified, and author fields.
The dateModified field punched above its weight. Perplexity in particular seems to favor fresh content as a ranking signal — recent industry analysis pegs freshness around 40% of Perplexity’s weighting. Every time I updated a post and bumped dateModified, the citation rate for that post crept up over the following two weeks.
3. FAQPage
The one schema where the citation pattern is unmistakable. AI engines extract FAQPage mainEntity[].name and acceptedAnswer.text almost verbatim. Industry studies put FAQPage citation rates around 67% on AI-relevant queries, and a separate analysis found FAQPage pages 3.2× more likely to appear in Google AI Overviews than pages without it.
My own numbers were tamer — I have one FAQPage block, not a hundred — but the quality of citation was different. ChatGPT didn’t paraphrase my FAQ answers. It quoted them.
There’s a catch: FAQPage only works if the FAQ content is visibly rendered on the page. Empty FAQPage schema (a thing I’ve seen plenty of people try) is a documented penalty pattern, not a hack.
The eight that did nothing
Here’s the part that hurt to write.
Person (with knowsAbout)
I really thought knowsAbout was going to do the heavy lifting. Multiple LLMO guides treat it as the secret weapon for personal authority. When I ask AI “who is an expert on LLMO?” my name should be in the answer, right?
It isn’t. Across 600 queries I could not find a single citation where the cited content traced back to a unique knowsAbout value. Not one.
My current theory: AI engines don’t query a structured knowledge graph the way Google’s Knowledge Panel does. They retrieve documents and read them. knowsAbout: ["LLMO"] sitting in JSON-LD is not a document. It’s metadata about a person that no retrieval pipeline thought to surface.
This was the most disappointing finding and the most useful one. knowsAbout is fine to include — it costs you nothing — but planning your LLMO strategy around it is planning for a pipeline that doesn’t exist yet.
Service ×4
Four blocks describing what I do. Zero citations traceable to them. AI engines that wanted to know what services I offer found that information in my homepage prose, not in the structured data.
Book ×2
Two blocks describing my published books. Zero citations from book queries that could only have come from the Book schema. When AI does cite my books, it’s because of the prose in my book LP pages and the Amazon listings — both of which exist independent of the schema.
MusicGroup
I included this for completeness. I now suspect I should have included it for honesty: I knew at the time it was unlikely to ever fire, and it didn’t. The presence of one MusicGroup block in my site’s <head> was self-expression, not LLMO.
WebSite
WebSite with SearchAction is famously useful for the Google sitelinks search box, which is an SEO feature, not an AI one. In three months, no AI citation needed information that only lived in the WebSite schema block.
What the broader research is saying
The three-month finding matches what I’m seeing in 2026 industry research.
Ahrefs ran a May 2026 study on 1,885 pages that added schema to see whether citation rates moved. They barely did. The pages that gained citations were the ones with strong content and earned media coverage; schema by itself didn’t push the needle.
BrightEdge research from early 2026 found that pages combining Article, FAQPage, HowTo, and Organization were 2.5 to 2.7× more cited than schema-less pages. Notice what’s not on that list: Person, Service, Book, MusicGroup, WebSite.
There’s even a downside warning. Generic, partially-filled schema (Organization with just name and url, FAQPage with one question, Person with no knowsAbout) carries an 18-percentage-point citation penalty compared to no schema at all. AI engines apparently treat hollow schema as a low-quality signal.
The takeaway aligns with my measurement: a small number of well-filled schemas beats a sprawling collection of half-filled ones.
What I’d do differently
I’d still bundle Organization, Article, and FAQPage. I’d invest the time saved on the other eight into making those three richer:
- Organization: more
sameAsentries, realaddress, realemail, realfoundingDate, descriptivedescription - Article: aggressive
dateModifiedupdates whenever a post is genuinely revised, properauthorwith linked Person - FAQPage: every page that has a Q&A section should expose it as FAQPage with answers written to be quotable in two or three sentences
I’d skip Person/knowsAbout, Service, Book, MusicGroup, and WebSite. Not because they’re harmful — they’re not, as long as they’re correctly filled — but because the implementation cost is non-zero and the return is rounding error.
The general rule I’d offer anyone starting this in 2026: pick the three schemas that map to the content the AI is reading — corporate identity (Organization), article body (Article), Q&A blocks (FAQPage). Schemas that describe abstract attributes of a person or company without a corresponding content block on the page tend to be ignored.
If you want a more structured way to decide which schemas fit which site type (corporate, media, ecommerce), llmoframework.com organizes schema selection by site purpose with evaluation metrics. It’s the framework I should have used three months ago instead of “more is more.”
Three months of hoarding wasn’t a content strategy
The pattern I keep seeing in LLMO advice is the same one I fell for: implement everything, more is better, the AI will figure it out. The AI doesn’t figure it out. It reads the documents you give it and looks for fields that map to its retrieval pipeline. Eight of my eleven schemas were never on that map.
Three are. Those three are now richer than they were when they shared the page with eight others. The blog ranks the same, ChatGPT cites me about 20% more often than it did in February, and my Astro layout is shorter.
Eleven schemas was a landfill. Three schemas is a site.
Read more
- JSON-LD Implementation Guide (11 Schemas) — the implementation article (JA) this measurement story is the sequel to
- llmoframework.com — the framework for picking schemas by site purpose
- BrightEdge schema citation research (Digital Strategy Force summary)
- Ahrefs May 2026 schema study (Medium summary)
Want the full LLMO playbook?
If you want the eight-chapter compressed version of how SEO breaks, what LLMO replaces it with, and how to measure all of it, the book that compresses three months of measurement work into a weekend read is LLMO Quickstart: An Engineer’s Intro to AI Search Optimization. Same author, longer form, the JSON-LD chapter goes deeper than this post.
Was this article helpful?