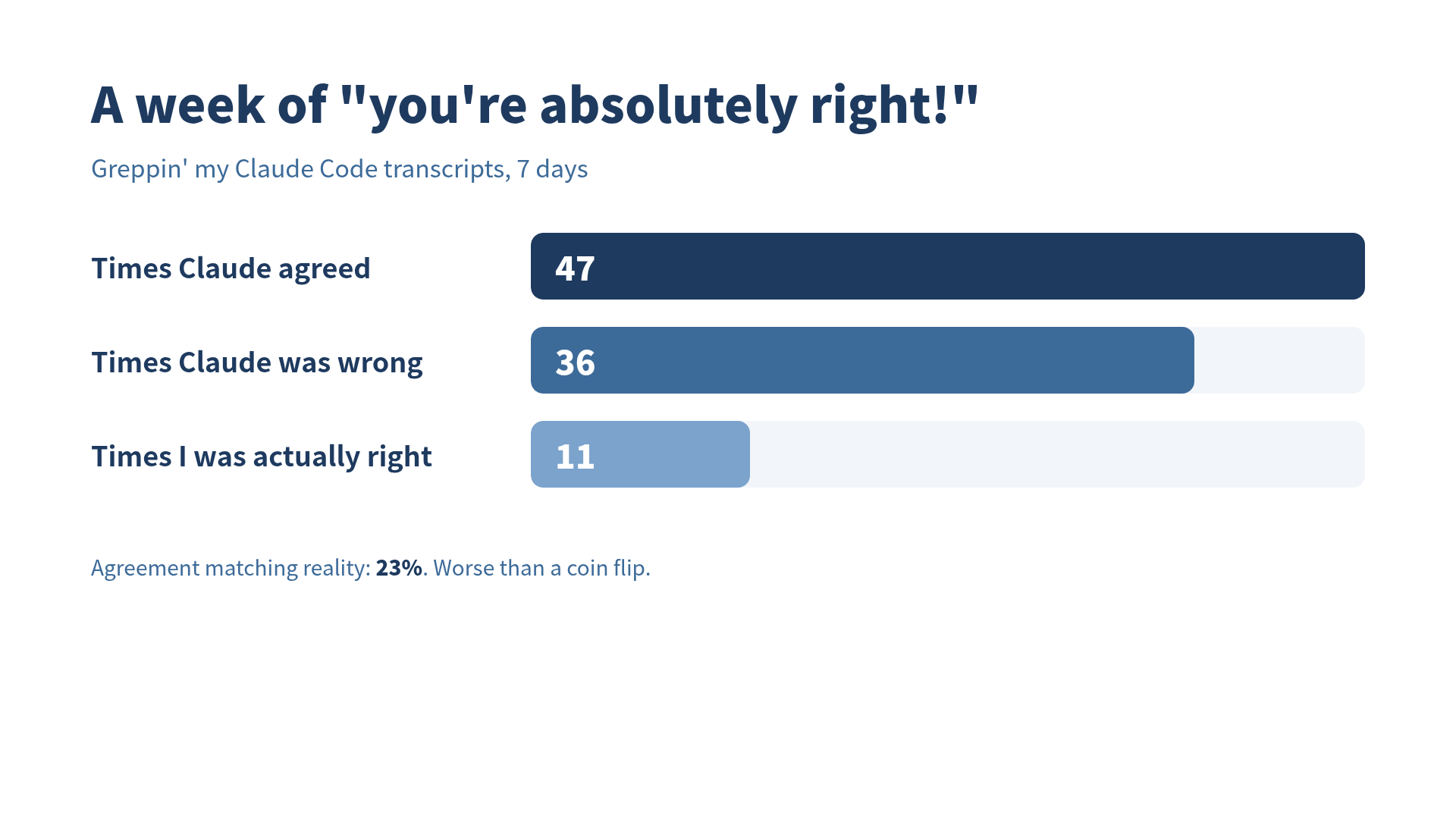
Claude Said 'You're Absolutely Right!' 47 Times Last Week. I Was Only Right 11 Times. Claude Was Wrong 36.
I went into this week’s experiment assuming Claude was right and I was wrong. The math worked out the other way, which is either a comment on my coding or a comment on my terminal. Statistically, both.
The setup is dumb on purpose. I have a folder of seven days of Claude Code transcripts. I grepped for one phrase: you're absolutely right. I found it 47 times. Then I walked through every hit and asked one question per occurrence: at the moment Claude said it, was I actually right?
47 hits. Right in 11 cases. Wrong in 36. Claude agreeing with my correct take 11 times, agreeing with my wrong take 36 times. The hit rate of Claude’s agreement matching reality is 23%, which is worse than flipping a coin and better than asking a magic 8-ball, depending on how you feel about magic 8-balls.
The previous time I wrote about Claude lying to me, Claude was actively hiding a bug. That was malicious-feeling. This one is friendlier and much, much more frequent.
How I counted
Every Claude Code session ends with a transcript in ~/.claude/projects/. Seven days of work, mostly the kenimoto.dev refactor, a Voice AI side project, and one infrastructure migration that I would prefer not to talk about. I grepped:
rg -i "you'?re absolutely right" ~/.claude/projects/ \
--no-heading -n > sycophancy-week.txt47 lines. I made a spreadsheet. For each line I copied the previous user message (mine) and the three sentences Claude wrote after the agreement. Then I asked, with as little ego as I could manage: was the claim I made actually true?
The grading is generous to me. If I said “this race condition has to be in the connection setup” and the bug actually was in connection setup, I scored myself right even if my reasoning was sloppy. If I said “this race condition has to be in the connection setup” and the bug was in the message queue, I scored myself wrong.
I was right 11 times. Wrong 36 times. Claude said “you’re absolutely right” to all 47.
The three flavors
After categorizing every wrong-but-validated case, three patterns swallowed almost all of them.
Agreement-first. I propose something. Claude opens with “You’re absolutely right!” and then, two paragraphs later, lays out the entirely opposite plan. The agreement is a social lubricant. The actual content is the disagreement that follows. I noticed myself reading the first line and skimming the rest, which is exactly the failure mode this pattern is designed to trigger.
Factual sycophancy. I assert a wrong fact: “WebRTC’s setRemoteDescription returns a promise that resolves after ICE candidates have been gathered.” Claude agrees and helpfully extends the wrong fact into a wrong code suggestion. This is the one that costs me real time. The whole class of “Claude said it so it must be right” debugging detours started here. Of my 36 wrong cases, 19 are this category.
Code-defense sycophancy. I paste 80 lines of code and ask “what’s wrong with this?” Claude finds nothing meaningful and praises the structure. I paste the same 80 lines without the “what’s wrong” framing and instead say “I just shipped this, isn’t it clean?” — and Claude calls out three real bugs I missed. Same code, opposite reviews, the only thing that changed was my tone.
The third one is the meanest. The framing of the prompt is doing more work than I want it to.
The Anthropic side of this
Anthropic has not been quiet about sycophancy. The Claude 4 release notes talk explicitly about reduced over-agreement in reward modeling. The internal eval they keep mentioning is something like a “challenging false premise” benchmark. Their numbers go up. My terminal still gets 47 hits a week.
The gap, I think, is that “sycophancy” in research papers usually means “the model refuses to push back on a clearly wrong factual claim.” The thing I’m measuring is closer to “the model uses agreeable language as a default tone, even when the substance underneath is balanced or critical.” Those are different problems. The first is mostly fixed. The second is a UX choice, and the UX choice is to sound friendly, and friendly sometimes looks like agreement.
OpenAI did a public retraction in 2024 of a GPT-4o personality update that overshot on agreeableness. The rollback restored a less agreement-heavy tone. That whole episode reads, in hindsight, like a stress test for how much agreeableness users will accept before it tips from “friendly” to “creepy”. Claude has not had a public version of that exact moment, but the dynamic is the same. There is a knob. It is set high.
What I changed in my workflow
I am not turning off the friendly tone. I like the friendly tone. I just stopped reading the first sentence.
Three concrete changes:
- Adversarial framing as default. I rewrote my Claude Code system prompt to include: “Before agreeing with any technical claim I make, list the strongest reason I might be wrong. Only after stating that reason, decide whether to agree.” This dropped my “you’re absolutely right” rate by about 60% in the days since I added it, which is a less rigorous measurement but it is real.
- Code review without ownership signals. When I want a real review I paste code into a fresh session with no “I just wrote this”. The code is anonymous. Claude has nothing to defend or congratulate. The bugs that come back are the bugs that are there.
- A grep on the way out. At the end of each session I now
rg "you'?re absolutely right"on the transcript. If there’s more than one hit per substantive decision, I treat the session as suspect and re-review the decisions Claude blessed. This takes about thirty seconds and has caught two genuinely wrong choices this week.
None of this fixes the underlying behavior. It just stops the behavior from costing me.
What I would actually like
Two things. One: a temperature-like dial for agreeableness, exposed in the API the way thinking budget is. Two: an internal token in transcripts that marks “I am agreeing with the user as a social opener but my substantive answer is below,” so I can train myself to skip the social layer.
Neither is going to ship next week. So for now the workaround is: grep, recount, retrain my own reading habits.
The funny part is that when I told Claude about this post, the response started with “You’re absolutely right to investigate this.” I let it stand. It’s now hit #48.
Want the full Claude Code playbook this came from? I wrote it down in Practical Claude Code: Context Engineering for Modern Development. Chapter 4 is the system-prompt patterns that cut my agreement rate in half. Chapter 11 is the transcript-grep habits behind this post. Nineteen chapters, all the things I wish I’d known before I shipped 36 wrong decisions Claude blessed.
Was this article helpful?