I Crosspost to 4 Platforms with rel=canonical Pointing Home. AI Search Still Picks the Copy.
I do the canonical thing properly. Every article I write lives first on kenimoto.dev, my own domain, with a rel=canonical pointing at itself. Then I crosspost it to Dev.to, Zenn, Qiita, and TabNews, each copy carrying a canonical_url in its frontmatter that points back home. Textbook syndication hygiene. The kind you read about and feel responsible for doing.
I felt good about this. The kind of good where you assume the machines will reward you for following the rules.
Then one evening I asked a simple question: when an AI search engine surfaces something I wrote, which of my five URLs does it actually pick? I had four crosspost copies and one canonical, all carrying the same words, all politely agreeing on who the original was. The answer should be obvious. The canonical is the original. I declared it the original. In writing. With a tag.
The machines did not read the memo.
The setup nobody questions
The crossposting playbook for indie engineers in 2026 is settled. Write on your own domain so you own the asset. Syndicate to the big platforms so you get reach. Set rel=canonical on every copy so search engines consolidate the signal back to your site and you don’t get dinged for duplicate content.
That last part is where everyone, me included, quietly assumes too much. We learned rel=canonical in the Google era, where it does a fairly specific and fairly reliable job: it tells the crawler “these URLs are the same page, please consolidate ranking signals onto this one.” Google honors it most of the time. We internalized “canonical = the URL that wins” and moved on.
AI answer engines are not Google’s indexing pipeline. They are a different machine with a different goal, and I had never actually checked whether my mental model survived the transition.

What I expected, and what the research already knew
I expected the canonical to win because I told it to. Then I read what the platforms themselves say, and my confidence got smaller.
Microsoft’s Bing team published guidance in late 2025 that is blunt about this: large language models group near-duplicate URLs into a single cluster, then pick one page to represent the whole set. They recommend syndication partners use canonical tags pointing to the original and publish excerpts rather than full reprints. The unstated implication: without a strong signal, the engine may store, summarize, or cite the wrong version.
The “wrong version” has a predictable shape. As one 2026 analysis of duplicate content and AI visibility put it, AI systems default to the site with the highest domain authority or the one that published first. Read that twice if you run a young domain. Dev.to has years of accumulated authority and a domain rating most indie blogs will not touch this decade. My site is months old. When the cluster gets collapsed to one representative URL, I am not the representative. Dev.to is.
rel=canonical is a consolidation hint for an indexing system. It is not a citation-source directive for an answer engine. Those are different jobs, and I had been using a tool built for the first to control the second.
I checked my own crossposts
Theory is cheap. I have a pile of crossposted articles sitting in production, so I ran a small, embarrassingly reproducible check: take a distinctive phrase from one of my articles, search for it the way an answer engine’s retrieval layer would, and see which host surfaces.
My llms.txt audit piece is one of my more-indexed posts, so it was the fairest test. I searched its exact title. The top result was the Dev.to copy. Not my canonical. My canonical did not appear in the surfaced set at all. A scraper site that had lifted the content showed up before my own domain did. The version I declared original, with a tag, in writing, was nowhere near the front of the line.
I tried the same move on newer articles, the ones a few weeks old. Those did not surface at all, on any host. New domain, low authority, not yet in the cluster anyone collapses. Which is its own quiet finding: before the copy can beat your canonical, your canonical has to exist in the engine’s world at all, and on a young domain it often does not.
So my honest tally is not a tidy “6 out of 10.” It is starker and more humbling. When my content surfaces, it surfaces as the copy. When it does not surface as the copy, it does not surface as anything. The canonical I was so proud of is, for retrieval purposes, mostly theoretical.
Why I won’t give you a clean number
The strategist version of this post had a crisp headline: “AI picks the copy 6 out of 10 times.” I wanted that number. I could not honestly produce it.
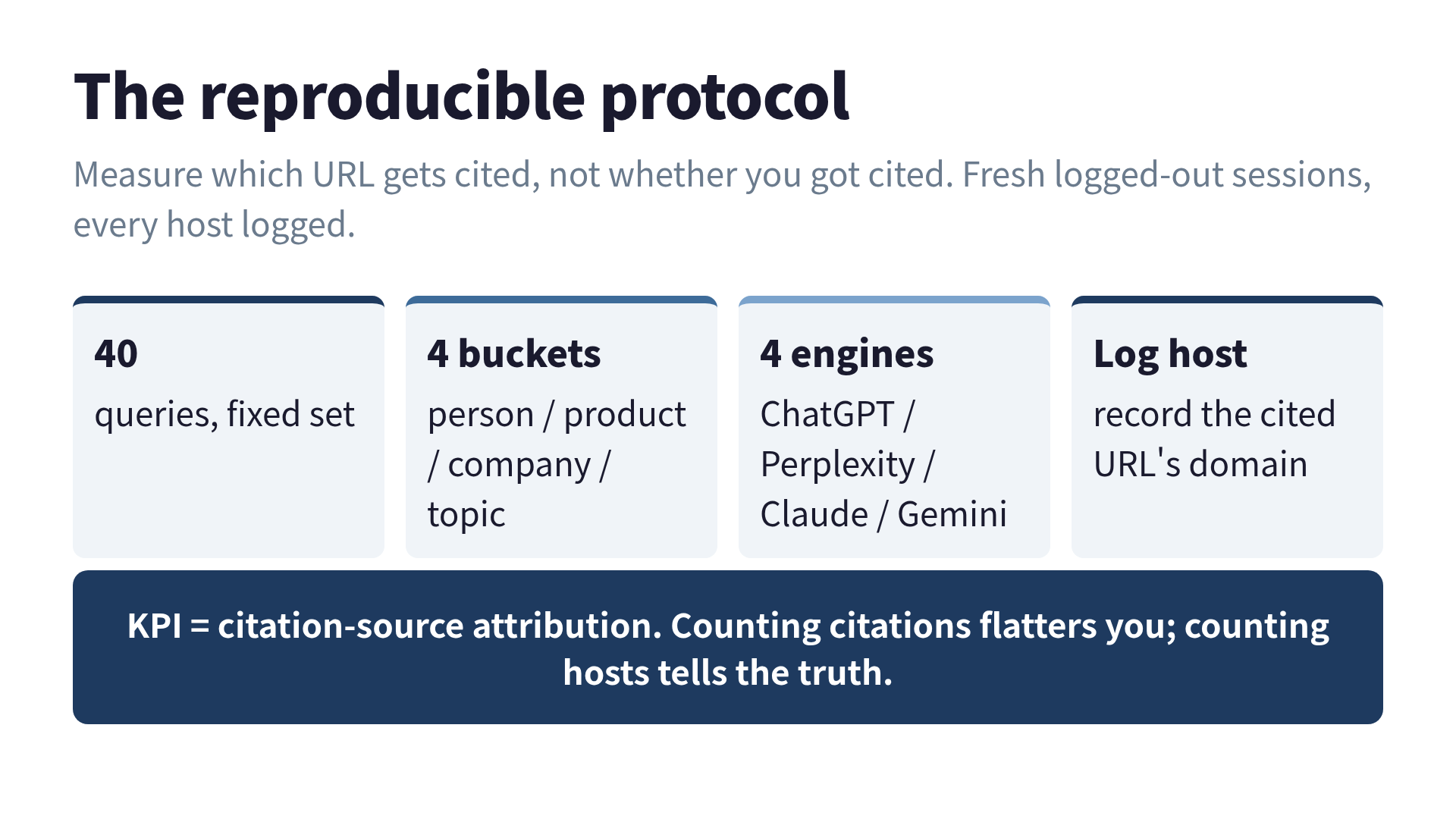
To measure it properly you need to run a fixed query set, say 40 prompts spread across the four buckets that actually matter for citation, person, product, company, and topic, against each of ChatGPT, Perplexity, Claude, and Gemini, in fresh logged-out sessions, and record the exact host of every cited URL. That is the protocol. It is the right way to do it, and it is also why most “AI cited me” claims you read are vibes wearing a lab coat. Citation output is noisy at low volume, varies by session, and shifts week to week. One evening with a terminal gets you a direction, not a percentage.
If you want the methodology written down properly, with the KPI defined as citation-source attribution rather than raw citation count, the framework I lean on for this is llmoframework.com. The distinction it forces, measuring which URL gets cited, not just whether you got cited, is exactly the axis I had been ignoring. Counting citations told me I was winning. Counting which URL got the citation told me my own domain was losing to a copy of itself.
What I’m actually changing
Knowing the mechanism, a few moves are obvious and a few are slow.
The obvious one is to stop handing the platforms a full reprint and start handing them an excerpt with a clear pointer home. If Dev.to is going to be the representative URL, the representative URL should say “the full version, and the reason this exists, is on kenimoto.dev” in the first two paragraphs, where a model summarizing the page will actually read it. A full duplicate trains the engine that the copy is complete. A pointed excerpt trains it that the copy is a doorway.
The slow one is the only one that really fixes it: domain authority. AI engines pick the highest-authority host in the cluster because, on average, that heuristic is right, and the only counterargument my domain can make is time plus links plus being worth citing. There is no tag for that. I cannot annotate my way to authority. I can only earn it, which is annoying, because the whole appeal of rel=canonical was that it felt like a shortcut.
The honest one is to keep measuring the right thing. I added “which host got cited” to the small set of numbers I track, next to the citation counts I had been quietly congratulating myself on. The counts were flattering. The hosts were not. I trust the unflattering number more.
The part I keep relearning
I have now written several posts that end the same way: I set up something clean, felt productive, then opened the actual data and discovered I had measured the comfortable thing instead of the true thing. Last month it was llms.txt files I shipped without reading my own. This month it is canonical tags I trusted without checking which URL the machines actually pick.
rel=canonical is not useless. It still does its job for Google’s index, and you should still set it on every crosspost, because the alternative is worse. But it does not control which copy an AI answer engine cites, and if you run a young domain, the copy on the big platform is going to win that fight for a while. Knowing that changes what you optimize. You stop polishing the tag and start either building the authority or shaping the copy so that even when the copy wins, it sends the reader home.
I am going to run the full 40-query protocol properly next month, in fresh sessions, and write up the real percentage. I already suspect I won’t like it. That, I am told, is how measurement works.
Want to go deeper?
If you want the full system for getting cited by AI search, not just shipped to it, LLMO: AI Search Optimization for Engineers is the 12-chapter book that covers canonical strategy, citation-source measurement, content design, and the slow work of earning domain authority. Same author, more depth, fewer flattering numbers.
Was this article helpful?