Claude Code Skills Cost Tokens Even When They Don't Fire. I Measured 5 Skills Across 7 Hours. The Bill Was 18%.
I thought Skills were a free upgrade over custom commands. They are not free. They are rent.
That sentence is the whole article in fifteen words. The rest is me showing my receipts.
I had five Skills loaded in one Claude Code session for seven hours on a Tuesday: a PR reviewer, a TypeScript migration helper, a database migration validator, a log tracer, and a CSV cleaner. Three of them never matched a single prompt the entire session. I checked the invocation log twice because I did not believe it. They sat there, quiet and well-behaved, and they still took roughly 18% of my total tokens for the day. The three that never fired were responsible for about 11% of the bill on their own.
I had been telling teammates that Skills only cost you tokens when they fire. I was wrong about that in a way that turned out to be measurable.
How Skills actually load (the part I had skimmed)
Here is the spec I had read but not internalized.
When your session starts, Claude Code reads every Skill in scope. The name and the description from each SKILL.md frontmatter are placed into the system context. The body of the Skill is not loaded yet. That part only loads when Claude decides the description matches your current prompt, or when you explicitly type /skill-name. Once the body is loaded, it stays in the context window until the session ends or compaction kicks in.
The implication I missed: the description is in the context on every single turn. Not just at session start. Every user message you send, every response Claude generates, the description sits there as part of the prompt. Five Skills with three-hundred-token descriptions is fifteen hundred tokens of “what these workflows can do” that gets re-billed on every turn.
Multiply by an eighty-turn session and you are paying for those descriptions one hundred and sixty times. They are not big. They are constant.
The setup
I run Claude Code as my daily driver. On the day I measured, I was doing what I usually do on a Tuesday: triaging PRs in the morning, then a long block of refactoring work, then some afternoon ad-hoc shell exploration. One Claude Code session, kept alive across all of it, with --output-format json --verbose piped to a logging wrapper so I could read the usage field on every response.
The five Skills loaded in ~/.claude/skills/:
| Skill | Description length | Purpose | Invoked? |
|---|---|---|---|
review-pr | ~310 tokens | PR review workflow | Yes (11 times) |
migrate-ts | ~290 tokens | TypeScript migration helper | Yes (2 times) |
migrate-db | ~340 tokens | DB migration validator | No |
trace-logs | ~270 tokens | Log file pattern tracer | No |
clean-csv | ~280 tokens | CSV cleaning recipes | No |
Total descriptions in context per turn: roughly 1,490 tokens of Skill metadata, sitting on top of CLAUDE.md, project context, and the live conversation.
The session ran 7 hours 12 minutes, 84 turns, total input and output tokens around 2.1M (with prompt caching active most of the way).
The receipt
I added up the token spend three ways: total, “would have been if no Skills were loaded” (estimated by subtracting the description-only overhead and the bodies of the two that actually fired), and the diff. The numbers from the logs:
| Category | Tokens | Share |
|---|---|---|
| Conversation, CLAUDE.md, code reads | 1,720K | 82% |
Active Skills (review-pr + migrate-ts) | 147K | 7% |
| Dormant Skills (descriptions, 3 never fired) | 231K | 11% |
| Total | 2,098K | 100% |
The two Skills that earned their keep cost me 7%. That is fine. They saved me probably twice as much in not having to retype workflow prompts.
The three that never matched anything cost me 11%. They earned exactly zero of it back. With prompt caching, the per-turn description cost is partially absorbed, but only partially: every time my prompt changes, the cache invalidates around the descriptions, and the input gets re-tokenized for billing in the input-token line. Eleven percent.
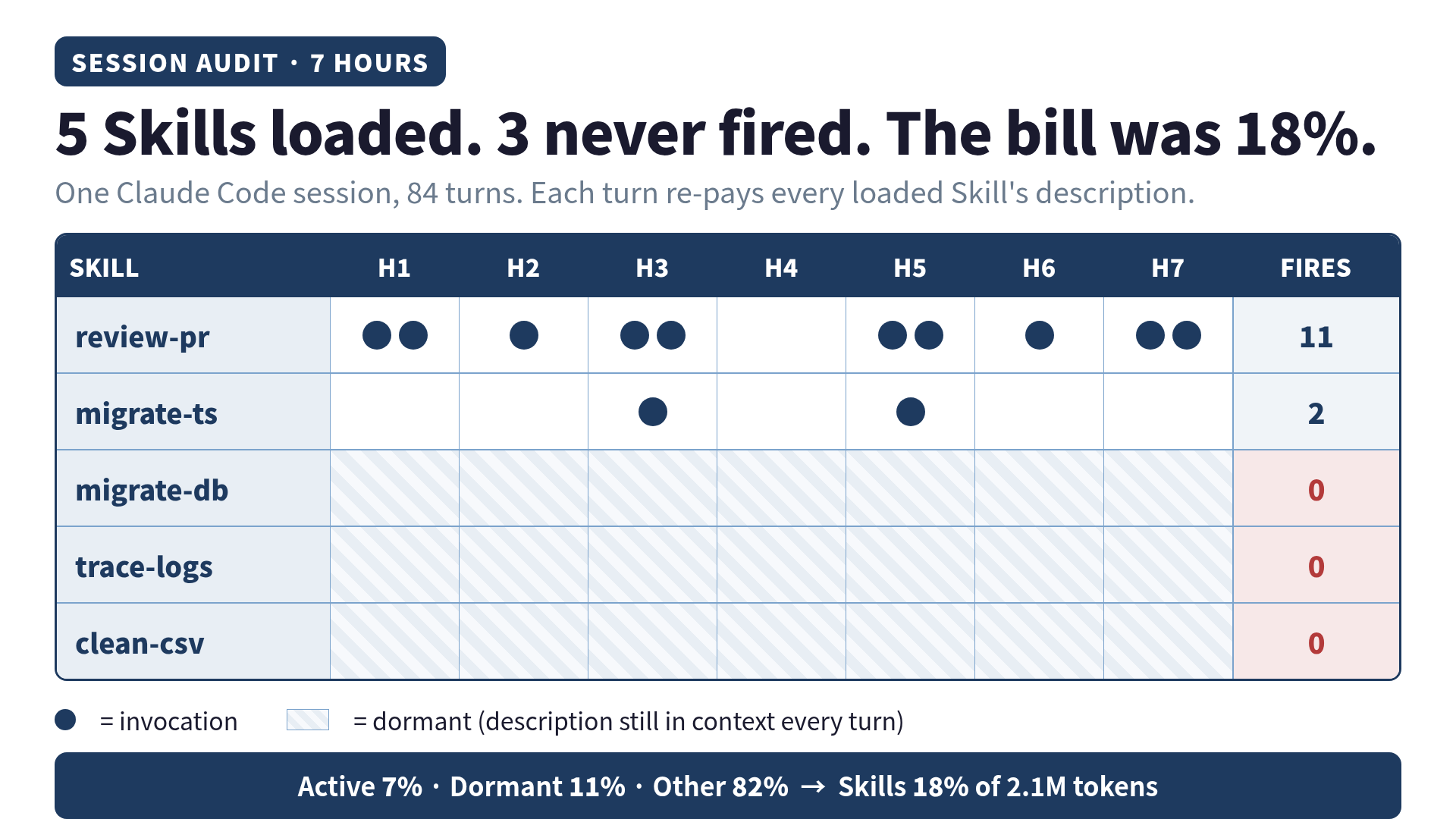
The audit
I ran the same workload the next morning with only the two Skills that had actually fired the day before. Same files, same PR set, same kinds of prompts. Total spend came in at 1,872K tokens. That is an 11% drop on the day, which lines up almost exactly with what the dormant descriptions had been costing me. Within the noise of a different day, it matches.
If you want a fast way to see this on your own setup, run a wrapper around claude that captures the JSON response:
claude -p "$YOUR_PROMPT" --output-format json --verbose \
| jq '{input: .usage.input_tokens, cached: .usage.cache_read_input_tokens, output: .usage.output_tokens}'The input_tokens line is the number you want to watch turn over turn. If it baseline-drifts upward after you add a Skill, you are paying description rent.
Why this surprised me
I had been thinking of Skills the way I thought of imports in a programming language: zero cost until called. Imports are zero cost because the compiler can throw away anything you don’t reference. Claude Code cannot. The description is the thing that tells Claude when to invoke the Skill at all, so the description has to be in the prompt every turn. If it were lazily loaded, the model could not decide to invoke the Skill in the first place.
That is the design tradeoff. It is the right one. But it means the marginal cost of “having a Skill installed but never using it” is not zero. It is a small per-turn tax that adds up over a long session.
This is not Hooks. Hooks are intentionally fired by Claude Code in response to events: pre-tool, post-tool, session-end. Hooks are not described in the system prompt for matching; they are configured in settings.json and triggered by the harness. The cost of an unused Hook is genuinely zero. The cost of an unused Skill is the description, every turn.
It is also not the same as an unused MCP server. An MCP server adds its full tool list to the system prompt at session start (which can be much bigger than a Skill description), but it is a one-time-per-server number that some teams have already measured (about 27,000 tokens per server in one published audit). Skills are a smaller per-item cost than an MCP server, but you tend to have more of them, and the per-turn pattern multiplies them out.
The five-step Skill audit
I now do this monthly. It takes ten minutes.
- List every Skill in scope.
ls ~/.claude/skills/plus your project-level.claude/skills/plus anything from plugins. Write them down. - For each Skill, find the last time it fired. If you run sessions with
--output-format jsonand pipe to a log, grep for the Skill name in the tool-use entries. If you do not log structured output, you have to guess from memory, which is usually wrong. - Mark anything with no invocations in the last 30 days as a candidate. You are not deleting them yet. You are flagging.
- Move candidates out of scope for a week. I literally
mvthe directory to~/.claude/skills-attic/. Live with it for a week. If you do not miss the Skill, it was rent. - Re-measure the input token baseline. Same kind of workload, no candidates loaded. If the input-token line is meaningfully smaller, you just found your savings.
The trap I want you to avoid: do not delete the candidate immediately. Sometimes a Skill that has not fired in 30 days is one you actually want for a quarterly task you forgot you do. Move-to-attic is the safe version.
What I changed in my own setup
Three Skills moved to the attic. One of them is coming back next month because I have a database migration coming up. The other two are probably gone for good. The two active Skills stayed.
The session I ran while writing this article is also down to two Skills. My input-token line on the per-turn log is now flat in a way it wasn’t before. Eleven percent does not sound dramatic when you say it out loud. On a heavy Claude Code Max plan, eleven percent of the monthly budget is real money. On the API metered plan, it is real money in a different way. Either way, it is money you are spending to keep three text files in context, which is a phrase I am embarrassed to type.
If you are running a lot of Skills, you are not wrong to like the convenience. You just have to know that the convenience has a per-turn tax, and that the tax is invisible until you go looking for it.
The phrase I am going to put on a sticky note above my monitor: loaded is not active, active is not invoked, and invoked is not the same as worth keeping.
Now go check your usage.input_tokens line. The number is right there in the JSON. It has been telling you this story the whole time.
For the full mental model of how Skills fit alongside Hooks, MCP servers, and sub-agents, plus the per-mechanism cost table I wish someone had handed me a year ago, I wrote about it in Claude Code Mastery. The context-window economics that makes the description-rent trick visible in the first place is in Context Engineering.
Was this article helpful?