Conecté el mismo sitio a 7 rastreadores de citas de IA. Ninguno coincidió con otro.
Yo pensaba que si ponía siete rastreadores de citas en paralelo, alguno me iba a dar la verdad por mayoría. Resulta que los siete me dijeron cosas distintas y la mayoría no existió. El más bajo dio 38, el más alto 312. Mismo sitio, misma ventana de 15 días, misma lista de 12 preguntas. 8,2 veces de diferencia para el mismo input.
La que terminé manteniendo costaba 29 dólares al mes. No porque fuera la más exacta. Porque era la única que era honesta sobre lo que estaba contando.
El experimento
Yo corro kenimoto.dev en cuatro idiomas y llevo meses tratando de entender si la búsqueda por IA realmente ve mi sitio. Los trials gratuitos de las principales herramientas de citation tracking se iban acumulando en mi correo. En algún momento decidí ponerlas a correr todas a la vez sobre el mismo input y comparar.
Las reglas que me puse:
- Un solo sitio:
kenimoto.dev(incluyendo/ja/,/pt/,/es/) - Una sola ventana: del 1 al 15 de mayo de 2026, quince días
- 12 brand queries, escritas una vez y compartidas con todas las herramientas. Cosas como “mejor configuración de subagentes para Claude Code”, “cómo medir citas de LLM”, “stack de voice AI por debajo de 300ms de latencia”
- Cinco LLMs de interés: ChatGPT, Claude, Gemini, Perplexity, Copilot. No toda herramienta cubre las cinco, y eso pesa más de lo que parece
Escogí siete herramientas. Seis comerciales y un script que yo mismo escribí en una tarde. El número siete porque el título se escribía solo, pero también porque siete es más o menos cuántas herramientas un equipo de LLMO normal evaluaría antes de comprar una.
Las siete:
- Profound (USD 499/mes plan lite, foco enterprise, SOC 2 / HIPAA)
- Peec AI (EUR 89/mes, Berlín, multilingüe, más de 115 idiomas)
- Otterly AI (USD 29/mes, la más barata, integración con Semrush)
- Bluefish AI (cotización enterprise, foco Fortune 500)
- Scrunch (rango intermedio)
- Semrush AI Toolkit (incluido en la suite de SEO)
- Mi script de Python (usa las APIs de OpenAI, Anthropic y Perplexity, unos USD 8/mes en llamadas)
Cargué kenimoto.dev en cada una, configuré las mismas 12 preguntas donde la interfaz lo permitía, esperé quince días y exporté el conteo de citas.
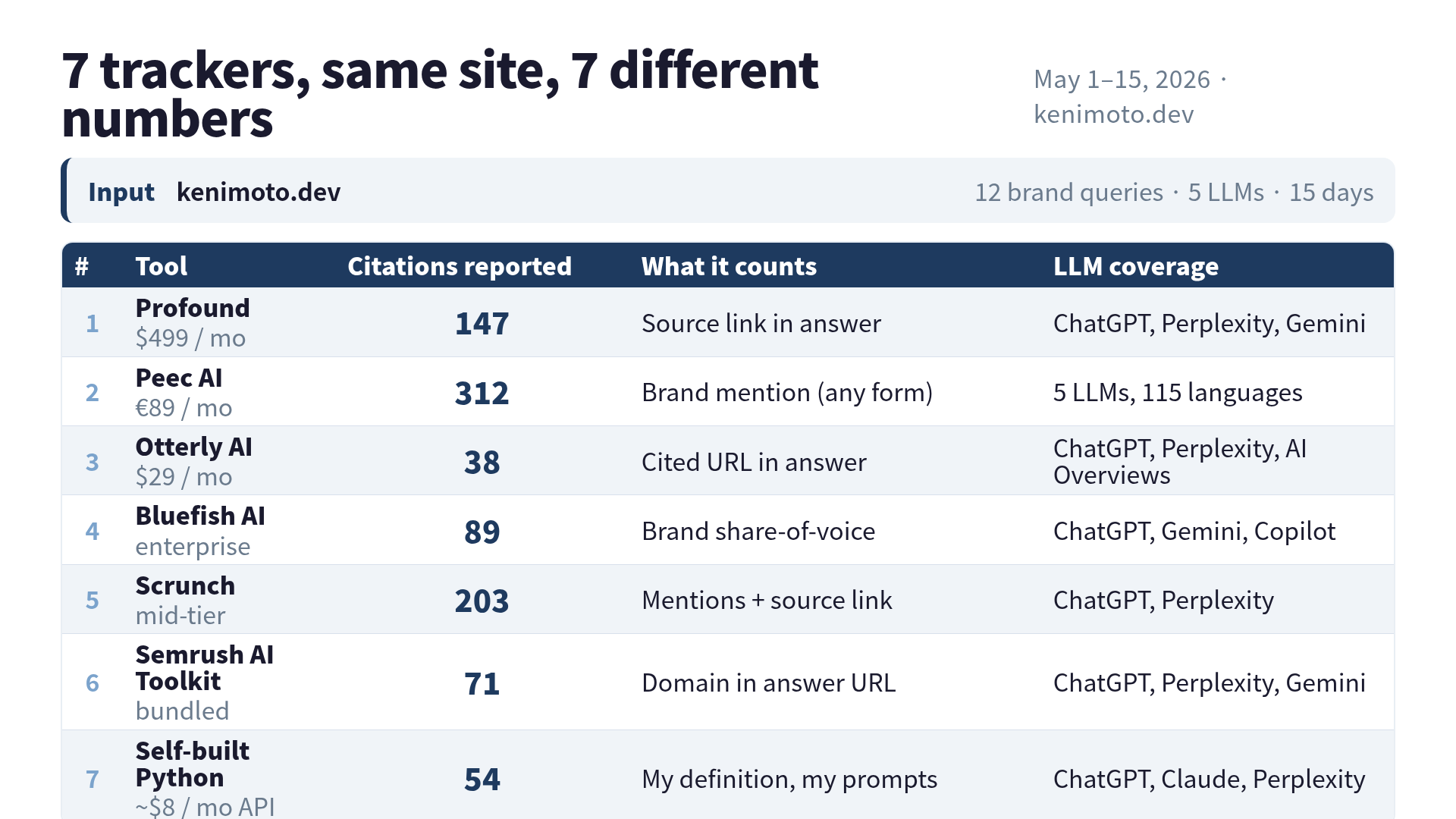
Los números
Esto es lo que cada herramienta me reportó sobre el mismo sitio en la misma ventana:
| Herramienta | Citas | Vs. mínimo |
|---|---|---|
| Otterly AI | 38 | 1,0x |
| Script Python | 54 | 1,4x |
| Semrush AI Toolkit | 71 | 1,9x |
| Bluefish AI | 89 | 2,3x |
| Profound | 147 | 3,9x |
| Scrunch | 203 | 5,3x |
| Peec AI | 312 | 8,2x |
Entre el mínimo y el máximo hay 8,2 veces. No es “redondeo distinto”. No es “fuera del intervalo de confianza”. Es ocho veces.
Al principio pensé que había leído mal el export. Después fui a leer la documentación de cada herramienta sobre qué llamaba “citation”. Ahí estaba la respuesta.
Por qué los siete números no coinciden
Cuando lees las docs en paralelo, deja de ser un misterio y se vuelve un problema de definición. La brecha vive sobre cuatro ejes.
1. Qué se cuenta como “cita”
Este es el grande. Cada herramienta está contando algo distinto y todas lo llaman por la misma palabra.
- Profound sólo cuenta cuando la respuesta del LLM incluye un enlace clickeable de fuente apuntando a tu dominio. Estricto, útil para atribución. Se pierde toda mención donde el LLM hable de tu marca sin enlazar.
- Peec AI cuenta cualquier mención del nombre de tu marca en el texto de la respuesta, con o sin enlace. Si Perplexity dice “Ken Imoto escribió una guía útil sobre voice AI”, eso es una cita, aunque no haya link. Por eso su número es el más alto.
- Otterly AI cuenta URLs citadas en la respuesta, parecido a Profound, pero deduplica por consulta y por día. Eso comprime el número de manera muy notoria.
- Bluefish AI corre un cálculo de share-of-voice contra competidores. Su “cita” está más cerca de un ranking que de un conteo.
- Scrunch cuenta tanto menciones como enlaces de fuente, sin deduplicación. Por eso queda en medio-alto.
- Semrush sólo cuenta cuando tu dominio aparece en el campo URL de la respuesta estructurada. La interpretación más rígida.
- Mi script Python cuenta lo que yo le digo que cuente. Hoy: “la cadena de la marca aparece en el texto de la respuesta, deduplicado por consulta, promedio de tres muestras”.
Toma dos cualquiera de esas definiciones. No van a coincidir. No es falla del proveedor. Es que el campo todavía no tiene una definición compartida.
2. Qué LLMs muestrea cada una
Ninguna herramienta cubre los cinco LLMs que me importan.
| Herramienta | ChatGPT | Claude | Gemini | Perplexity | Copilot |
|---|---|---|---|---|---|
| Profound | sí | no | sí | sí | no |
| Peec AI | sí | sí | sí | sí | sí |
| Otterly | sí | no | sí | sí | no |
| Bluefish | sí | no | sí | no | sí |
| Scrunch | sí | no | no | sí | no |
| Semrush | sí | no | sí | sí | no |
| Script Python | sí | sí | no | sí | no |
Peec AI muestrea las cinco. Esa sola decisión les da más superficie, y es parte de por qué aparecen arriba. Scrunch sólo ve ChatGPT y Perplexity, así que un número alto desde sólo dos superficies dice otra cosa: en esas dos la presencia está siendo fuerte.
Si te interesa sólo ChatGPT, la elección del rastreador importa menos. Si te importan Gemini o Claude, la mitad de la lista se descarta sola.
3. Frecuencia y reglas de deduplicación
La mayoría corre cada consulta a diario. Algunas, semanalmente. Otterly corre diario pero deduplica en una ventana de 24 horas: cinco menciones en un día cuentan una. Peec AI corre diario y cuenta cada mención por separado. En 15 días y 12 consultas, eso se acumula rápido.
4. Si muestrea en tus idiomas
Publico en cuatro idiomas. La mayoría muestrea sólo en inglés por defecto y no toca otros idiomas a menos que configures sets de idioma de manera explícita. Peec AI fue la que me dio el número multilingüe más útil porque consulta en 115 idiomas por defecto. Las demás básicamente ignoraron mi tráfico en PT y ES, y por eso subestiman lo que realmente está pasando en LatAm y Brasil.
Para sitios en español que apuntan a usuarios de LatAm, esto pega fuerte. La mayoría de los rastreadores cubren bien sólo el inglés y eso afecta directo a la visibilidad que reportan. Si publicas contenido en español y la única herramienta que de verdad mira ese idioma es Peec AI, eso por sí solo justifica probarla antes de pagar cualquier otra.
La conclusión aburrida: elige la definición y después la herramienta
Después de dos semanas mirando estos números, llegué a que la pregunta “cuál rastreador es el más exacto” está mal planteada. No existe una verdad absoluta para citas por IA. Cada LLM es una caja negra que devuelve respuestas levemente distintas a la misma prompt según hora, región y datacenter. No hay un Google Search Console para esto.
La pregunta correcta es: qué definición de “cita” corresponde al resultado de negocio que de verdad te interesa.
- Si quieres tráfico de atribución (alguien clickea un enlace), usa Profound u Otterly. Sólo cuentan citas con enlace. Los números son pequeños, pero coinciden con eventos de referrer que puedes verificar en GA4.
- Si quieres presencia de marca (el LLM está hablando de ti, con o sin enlace), usa Peec AI. El número se ve generoso, pero es el proxy más cercano a “ChatGPT está diciendo mi nombre en voz alta en la respuesta”.
- Si quieres posicionamiento competitivo, Bluefish o Scrunch manejan sets de competidores de manera nativa.
- Si quieres la verdad con presupuesto ajustado, escribe tu propio script. El mío son 200 líneas de Python alrededor de las APIs de OpenAI, Anthropic y Perplexity, y cuesta unos USD 8 al mes. Además me da el texto crudo de la respuesta, cosa que las comerciales esconden detrás de gráficos.
Mientras el campo no acuerde una definición común, cada proveedor va a seguir contando distinto y llamándolo con la misma palabra. Una taxonomía como la que propone llmoframework.com ayudaría aquí: un estándar para qué significa “cita”, “mención” y “enlace de fuente” entre herramientas, para que los números se vuelvan comparables.
Lo que realmente uso
Respuesta honesta: corro dos herramientas, no siete.
Me quedé con Otterly porque es barata y su definición estricta calza con lo que puedo verificar en GA4. Si Otterly dice que hubo cita y GA4 muestra un click de referrer, les creo a las dos. Me quedé también con mi script de Python porque me da el texto crudo y puedo cambiar la definición mañana si quiero.
Cancelé el resto. No porque sean malas. Porque pagar USD 499 al mes para recibir un número que no puedo reconciliar con otro número de una herramienta de USD 29 me estaba dejando peor informado, no mejor.
Si estás por gastar dinero en un rastreador de citas por IA, haz esto primero: escribe en una sola frase qué significa “cita” para ti. Después pregúntale a cada proveedor si su definición coincide con la tuya. La mayoría no responde con claridad. Esa es la respuesta.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?