AIエージェントが「空気を読めない」本当の理由:常識ナレッジグラフという欠けたレイヤー
私のエージェントは、英語の論文を要約させれば博士みたいな顔をするくせに、同僚が「大丈夫です」とキーボードを強めに叩いている状況を渡すと、本気で「では問題なさそうですね」と返してきます。賢いのに、空気が読めない。最初はプロンプトが悪いのだと思っていました。違いました。足りなかったのは指示の質ではありません。知識のレイヤーがまるごと欠けていたのです。
その欠けたレイヤーの名前が、常識ナレッジグラフです。
RAGで足りるはずだった、という思い込み
私はしばらく、エージェントに足りないものは全部RAGで埋まると思っていました。知らないことがあるなら、検索して文脈に入れればいい。実際、事実の欠落にはこれがよく効きます。「GraphRAGの開発元は?」と聞かれて「Microsoft Research」と答える、その手の問いは検索でカタがつく。
ところが、人間が日常的にやっている推論の多くは、検索で出てくる事実ではありません。
「彼女は試験に落ちたと聞いた」と言えば、私たちは即座に「落ち込んでいるだろう」と推測します。どこにも「試験に落ちた人は悲しい」とは書いていないのに、です。検索しても、これは出てきません。世界の動き方についての暗黙の前提だからです。LLMはこの種の推論が、流暢さのわりに驚くほど安定しません。Karpathyが「ギザギザの知能(jagged intelligence)」と呼んだ、あの段差です。要約は超人的なのに、言外の感情はぽろっと外す。
RAGは「知らない事実」を埋める仕組みです。常識ナレッジグラフは「言わなくても分かるはずのこと」を埋める仕組みです。役割が違います。

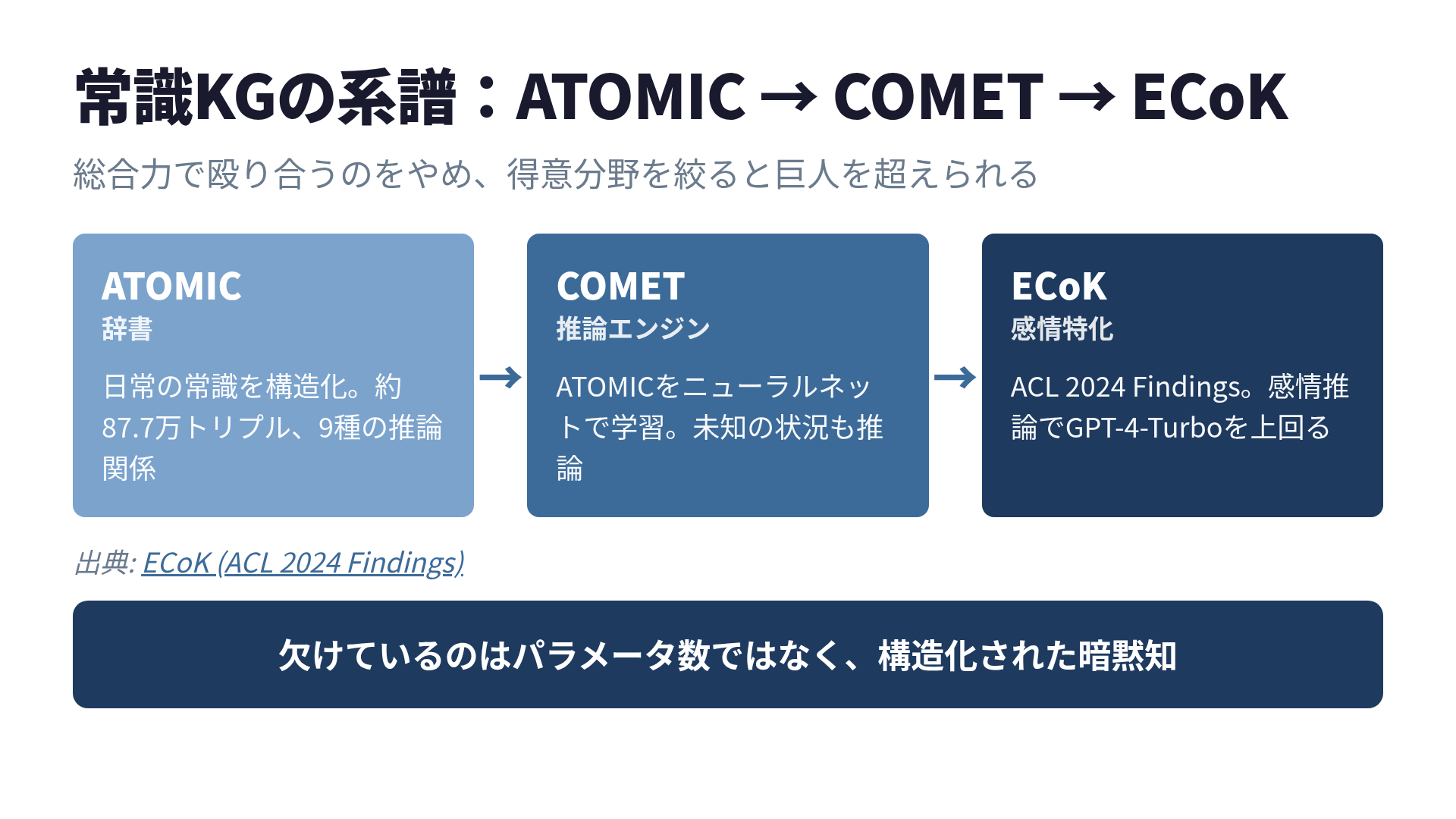
ATOMIC、COMET、ECoK
このレイヤーには、ちゃんと歴史があります。
ATOMIC(Atlas of Machine Commonsense)は、日常的な出来事の常識を構造化したナレッジグラフです。「PersonXが試験に落ちる」というイベントに対して、if-then形式で推論を持っています。
イベント: 「PersonXが試験に落ちる」
→ xReact(Xの感情): 悲しい、失望する、恥ずかしい
→ xWant(Xが望むこと): 再挑戦する、慰めを求める
→ oReact(他者の感情): 心配する、同情するATOMICは9種類の推論関係で、約87万7,000トリプルを持ちます。辞書だと思ってください。引けば常識が出てくる。
COMET(COMmonsense Transformers)は、そのATOMICをニューラルネットに学習させ、辞書に載っていない状況にも常識推論を生成できるようにしたモデルです。ATOMICが辞書なら、COMETは推論エンジン。「PersonXが深夜まで仕事をする」という未知の入力にも、「疲れる」「達成感を感じる」「他者は心配する」と返せます。
そしてECoK(Emotional Commonsense Knowledge Graph)。2024年のACL Findingsで発表された、感情に特化した常識KGです(ECoK: ACL 2024 Findings)。心理学・認知科学・言語学の理論をKGに統合し、感情を単純なラベルで終わらせず、強度・原因・対象まで構造化しています。
ここが面白いところで、ECoKで学習したCOMET-ECoKは、感情推論タスクでGPT-4-Turboを上回りました。汎用の巨大LLMが「何でも80点」だとすると、特化型KGは「この領域だけ95点」を取りに行ける。総合力で殴り合うのをやめて、得意分野を一つに絞ると巨人を超えられる、という良い例です。私のような個人開発者には、地味に勇気の出る話でもあります。
エージェント設計に、どう足すか
理屈はいいとして、では実際にどうエージェントに組み込むのか。私が腹落ちしたのは、KGとLLMを補完関係として置く考え方でした。
LLMだけに頼ると、自信満々に「東京タワーは634メートルです」と言い切る同僚みたいになります。間違っているのに態度だけは堂々としている。KGはその同僚の隣に座る、無口だけど正確なファクトチェック係です。逆にKGだけだと、自然言語で問い合わせるのも、テキストから新しい関係を抽出するのも苦手。そこはLLMが補う。
常識レイヤーを足すときの実装パターンは、だいたいこの形に落ち着きます。
- 発話やイベントをCOMETに通す。「実は資料がまだ…」という入力から、xReact = [不安, 焦り, 申し訳なさ] のような感情・因果の推論を生成する。
- その推論をエージェントの文脈に追加ノードとして渡す。対話をグラフとして扱い、時系列・話者・常識の3種のエッジで結ぶCEICGのようなアーキテクチャ(RoBERTa + LSTM + GCN)が、文脈と常識の両方を見て応答を組み立てます。
- 役割分担を崩さない。事実はRAGに、暗黙知は常識KGに。両方を一つのプロンプトに詰め込んで「よしなにやれ」と祈らない。
地味な工程です。vibe codingみたいな爽快感はありません。でも、エージェントが「大丈夫です」の裏を読めるかどうかは、この地味なレイヤーがあるかどうかで決まります。
まとめ
- LLMが「空気を読めない」のは指示不足ではなく、暗黙知のレイヤーが欠けているから
- RAGは事実の欠落を、常識ナレッジグラフは言外の前提・因果・感情を埋める。役割が違う
- ATOMIC(辞書)→COMET(推論エンジン)→ECoK(感情特化)という系譜があり、COMET-ECoKは感情推論でGPT-4-Turboを上回った
- エージェントにはRAGと常識KGを補完関係として組み込み、役割分担を崩さないのが実装の勘所
賢いのに常識がない、という弱点は、より大きなモデルを待つことでは埋まりません。欠けているのはパラメータ数ではなく、構造化された暗黙知のレイヤーだからです。
この常識KGの系譜や、感情推論をエージェントに組み込む具体的なアーキテクチャは、書籍のほうで手を動かしながら追えるようにまとめています。
この記事は役に立ちましたか?