同じサイトを7つのAI引用トラッカーに入れたら、7つとも違う数字を返してきた
私は最初、7つのトラッカーを並べれば多数決で正解が出ると思っていました。実際に並べたら、7つとも違うことを言っていて、多数決すら成立しませんでした。
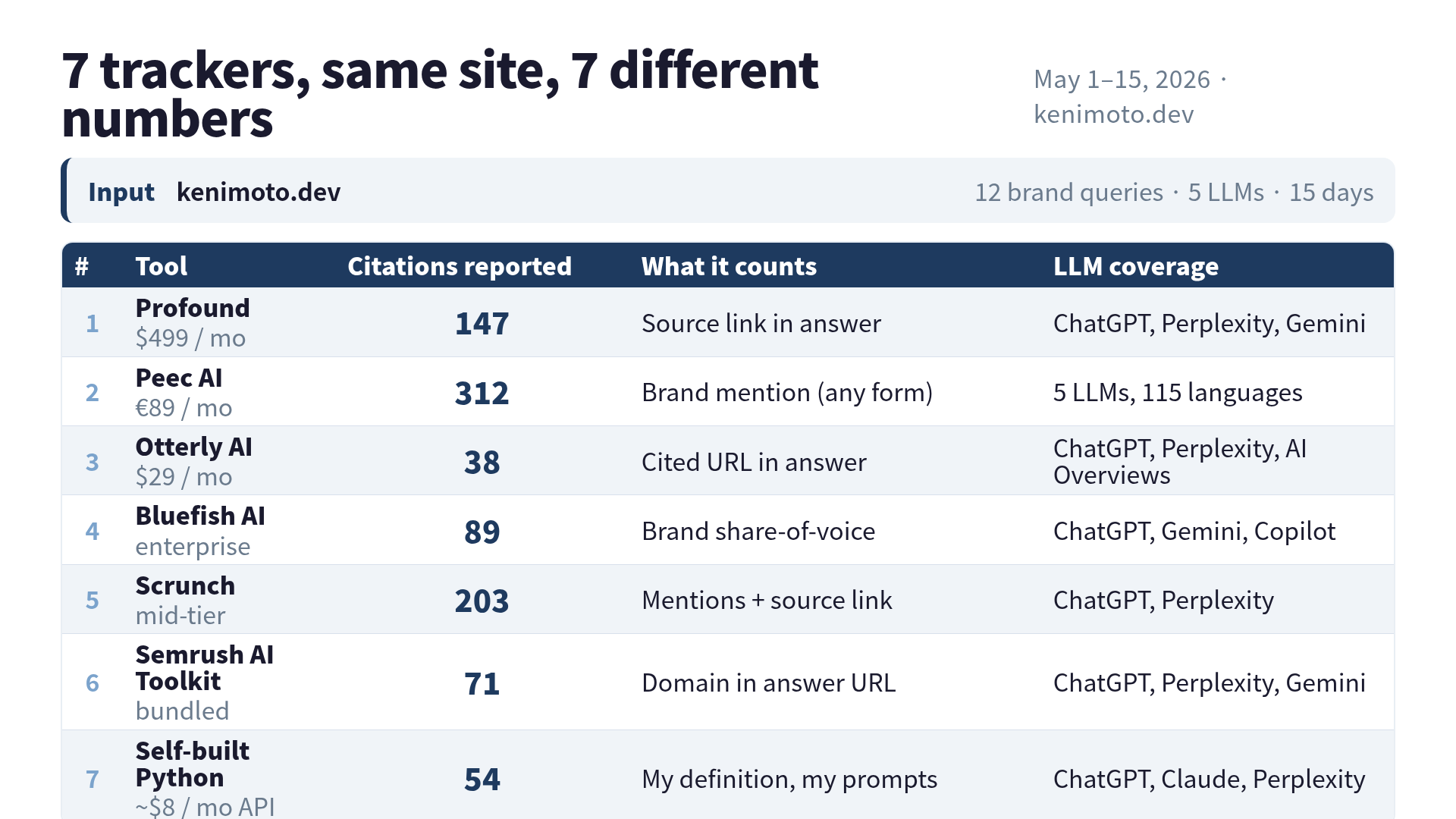
最小値は38、最大値は312。同じサイト、同じ15日間、同じ12クエリです。倍率にして 8.2 倍の開きでした。先に結論を書くと、私が最後まで残したのは月29ドルの一番安いやつでした。理由は「一番正確だったから」ではなく「自分が何を数えているか正直に書いてあったから」です。
計測の前提
私は kenimoto.dev を4言語で運用しています。AI検索が本当にこのサイトを見ているのか、ずっと気になっていました。気がついたら、各社の無料トライアルが受信箱に溜まっていたので、全部いっぺんに同じ条件で走らせてみたわけです。
自分に課したルールは次の4つです。
- 対象サイトは kenimoto.dev 一本に絞る(/ja/、/pt/、/es/ も含む)
- 計測期間は 2026年5月1日から5月15日までの15日間
- 12個のブランドクエリを一度だけ作り、全ツールで共通利用する
- 5つのLLM(ChatGPT、Claude、Gemini、Perplexity、Copilot)への参照を見たい
12個のクエリは、たとえば「Claude Code のサブエージェント構成のおすすめ」「LLM 引用の計測方法」「300ms以下の音声AIスタック」など、私のコンテンツが元々狙っている領域から選びました。
ツールは7つ選びました。商用が6つ、自前のスクリプトが1つです。7という数字にこだわったのは見出しのためですが、現実的にLLMO担当者が比較検討する候補数も大体これくらいです。
採用したツールは以下の通りです。
- Profound(月499ドル、エンタープライズ向け、SOC2 / HIPAA対応)
- Peec AI(月89ユーロ、ベルリン拠点、多言語に強い、115言語以上)
- Otterly AI(月29ドル、最安、Semrush 連携あり)
- Bluefish AI(要問い合わせ、Fortune 500 向け)
- Scrunch(中位帯の可視性計測ツール)
- Semrush AI Toolkit(既存SEOスイートに同梱)
- 自前のPythonスクリプト(OpenAI、Anthropic、Perplexity の API 利用、月8ドル相当)
各ツールに kenimoto.dev を登録し、UI が許す範囲で12クエリを共通設定にし、15日間放置してエクスポートしました。
数字
同じサイトに対して、各ツールが返してきた引用数は以下のとおりです。
| ツール | 引用数 | 最小値との比 |
|---|---|---|
| Otterly AI | 38 | 1.0倍 |
| 自前 Python | 54 | 1.4倍 |
| Semrush AI Toolkit | 71 | 1.9倍 |
| Bluefish AI | 89 | 2.3倍 |
| Profound | 147 | 3.9倍 |
| Scrunch | 203 | 5.3倍 |
| Peec AI | 312 | 8.2倍 |
最小と最大の差は 8.2 倍です。誤差とか丸めの話ではなく、まるごと別の値です。
最初は私もエクスポート結果を読み違えたのかと思って、各社のドキュメントを並べて読み直しました。答えはそこにありました。
なぜ 7 つの数字が割れたのか
各社のドキュメントを横並びで読むと、これはバラツキではなく「定義の問題」だと分かります。バラツキの軸は4つあります。
1. 「引用」の定義そのものが違う
これが一番大きい要因でした。各ツールは違うものを数えていて、それを全部「citation」と呼んでいます。
- Profound は、LLM の回答にあなたのドメインへのクリック可能なソースリンクが含まれている場合のみカウントします。厳格でアトリビューションには使えますが、リンクなしの言及は全部こぼれます。
- Peec AI は、回答テキストにブランド名が出たら全部カウントします。リンクの有無は問いません。Perplexity が「Ken Imoto が書いたこのガイドが参考になる」と言ったら、リンクなしでも1カウントです。これが最大値の理由です。
- Otterly AI は Profound に近く、ただし「同一クエリ・同一日」で重複を排除します。それで数字が大きく圧縮されます。
- Bluefish AI は競合との Share of Voice 計算を返します。引用数というよりも順位に近い指標です。
- Scrunch はブランド言及とソースリンクの両方をカウントし、重複排除なしです。中の上ぐらいの数値になります。
- Semrush は構造化された回答の URL フィールドにあなたのドメインが出た場合のみカウントします。最も厳格な解釈です。
- 自前 Python は私が決めた通りに数えます。今は「回答テキストにブランド文字列が出る、クエリごとに重複排除、3サンプル平均」です。
この中の任意の2つの定義は、絶対に一致しません。これはベンダーが悪いのではなく、業界がまだ「引用とは何か」の共通定義を持っていない、という話です。
2. サンプリング対象の LLM が違う
私が気にしている5つの LLM のうち、全部をカバーしているツールはほぼありません。
| ツール | ChatGPT | Claude | Gemini | Perplexity | Copilot |
|---|---|---|---|---|---|
| Profound | ○ | × | ○ | ○ | × |
| Peec AI | ○ | ○ | ○ | ○ | ○ |
| Otterly | ○ | × | ○ | ○ | × |
| Bluefish | ○ | × | ○ | × | ○ |
| Scrunch | ○ | × | × | ○ | × |
| Semrush | ○ | × | ○ | ○ | × |
| 自前 Python | ○ | ○ | × | ○ | × |
Peec AI だけが5つ全部を見ています。それだけでサンプリング面積が大きく、最大値になる理由のひとつです。Scrunch は ChatGPT と Perplexity の2つだけしか見ていないのに数字が大きいので、その2つの面で実際に多く引用されているとも読めます。
ChatGPT だけを気にしているなら、どのトラッカーを選んでも大差ありません。Gemini や Claude が重要なら、選択肢は半分以下になります。
3. サンプリングの頻度と重複排除のルール
ほとんどのツールは各クエリを毎日走らせます。一部は週次です。Otterly は毎日走らせますが、24時間以内の重複を排除します。1日に5回言及されても1カウントです。Peec AI は毎日走らせて毎回別カウントです。15日 × 12 クエリの規模だと、これが効いてきます。
4. 多言語に対応しているか
私は4言語で公開しています。多くのツールはデフォルトで英語のみサンプリングし、明示的に言語セットを設定しないと他言語を見ません。Peec AI が一番役に立つ多言語数値を返してきた理由は、115言語をデフォルトで見にいくからです。他のツールは PT と ES のトラフィックをほぼ無視していて、結果として LatAm とブラジルで実際に起きていることを過小評価しています。
つまらない結論: 定義を選んでから、ツールを選ぶ
2週間この数字を眺めて分かったのは、「どのトラッカーが一番正確か」という問いがそもそも間違っているということです。AI 引用には正解がありません。LLM はブラックボックスで、同じプロンプトでも時刻・地域・データセンターによって違う回答を返します。Google Search Console のような確定的なソースが存在しないのです。
正しい問いは「自分のビジネス成果に対応する『引用』の定義はどれか」です。
- アトリビューション流入(誰かが実際にリンクを踏む)を見たいなら、Profound か Otterly が向きます。リンク付き引用だけをカウントするので、数字は小さくなりますが GA4 のリファラデータと照合できます。
- ブランド存在感(リンクの有無を問わず、LLM があなたを言及している)を見たいなら、Peec AI が良いです。数字は大きく見えますが、「ChatGPT が回答の中で私の名前を口にしている」という事実に最も近いプロキシです。
- 競合ポジショニングを見たいなら、Bluefish か Scrunch が競合セットをネイティブに扱います。
- 予算を抑えつつ自分で真実を握りたいなら、自前スクリプトが一番です。私のは OpenAI、Anthropic、Perplexity の API を200行のPythonでラップしただけで、月8ドル前後です。生の回答テキストも取れるので、商用ツールがグラフの奥に隠している部分まで grep できます。
業界が共通定義を持つまでは、どのベンダーも違う数え方をして同じ単語を使います。llmoframework.com が提案しているような分類軸が広まれば、ツール間の数字が初めて比較可能になります。
結局、私が残したツール
正直に書きます。私が今も使っているのは7つのうち2つだけです。
Otterly は残しました。安いし、厳格な定義が GA4 で検証可能だからです。「Otterly が引用ありと言っていて GA4 にもリファラクリックがある」のなら、両方信じます。自前 Python スクリプトも残しました。生テキストが取れるし、定義を明日変えたければ即変えられるからです。
残りは解約しました。悪いツールだからではありません。月499ドル払って、月29ドルのツールと整合しない数字を得ても、自分が賢くなるのではなく、むしろ判断が鈍るからです。
これから AI 引用トラッカーに金を出そうとしているなら、まず1文で「自分にとっての引用とは何か」を書いてみてください。次にベンダーに聞いてみてください、「あなたの定義は私の定義と一致しますか」と。多くは即答できません。それが答えです。
続きはこちら
この計測問題について、私が使っているPythonスクリプトと GA4 設定までまとめて書籍にしました。
この記事は役に立ちましたか?