コードレビューを6段階にしたら、AIと人間の分業が見えた
私は最初、AIに Logic 層を任せて3つのバグを通しました。
エッジケースの判定漏れ、空配列の扱いミス、外部APIのリトライ条件のずれ。 CodeRabbit も Copilot も指摘しなかったし、私自身も「AI が見たから大丈夫」と思って Approve を押していました。本番でデータが10件だけずれていることに気づいたのは、リリースの3日後です。
数字としては小さいバグでした。でも怖かったのは「自分のレビュー判断が信用できなくなった」という感覚です。 AI が見落としたのは仕方ないにしても、私自身がコードを読んで Approve を押したという事実が残ります。何を見て、何を見落としていたのか、自分でも説明できませんでした。
それ以来、「AI と人間の境界線」を真面目に引きました。3層モデルを使っていたのですが、3層だと粒度が粗すぎて、 Logic 層に全部の責任が押しつけられていたのが原因でした。そこで6段階に切り直したら、どの段階を誰が見るべきかがやっと見えてきました。
この記事は、その6段階の話です。
3層モデルとは別の切り口
私は以前、 レビューの3層モデルという記事 を書きました。自動ゲート、AIレビュー、人間レビューの3層で分業する設計の話です。
その記事は「誰が何を見るか」という大きな構造の設計でした。今回の6段階は別の切り口です。 「AI と人間の境界線はどこで切れるのか」 を、もう一段細かく解像度を上げて見るための整理です。
3層モデルは設計図、6段階は設計図に書き込まれた寸法、というイメージで読んでください。
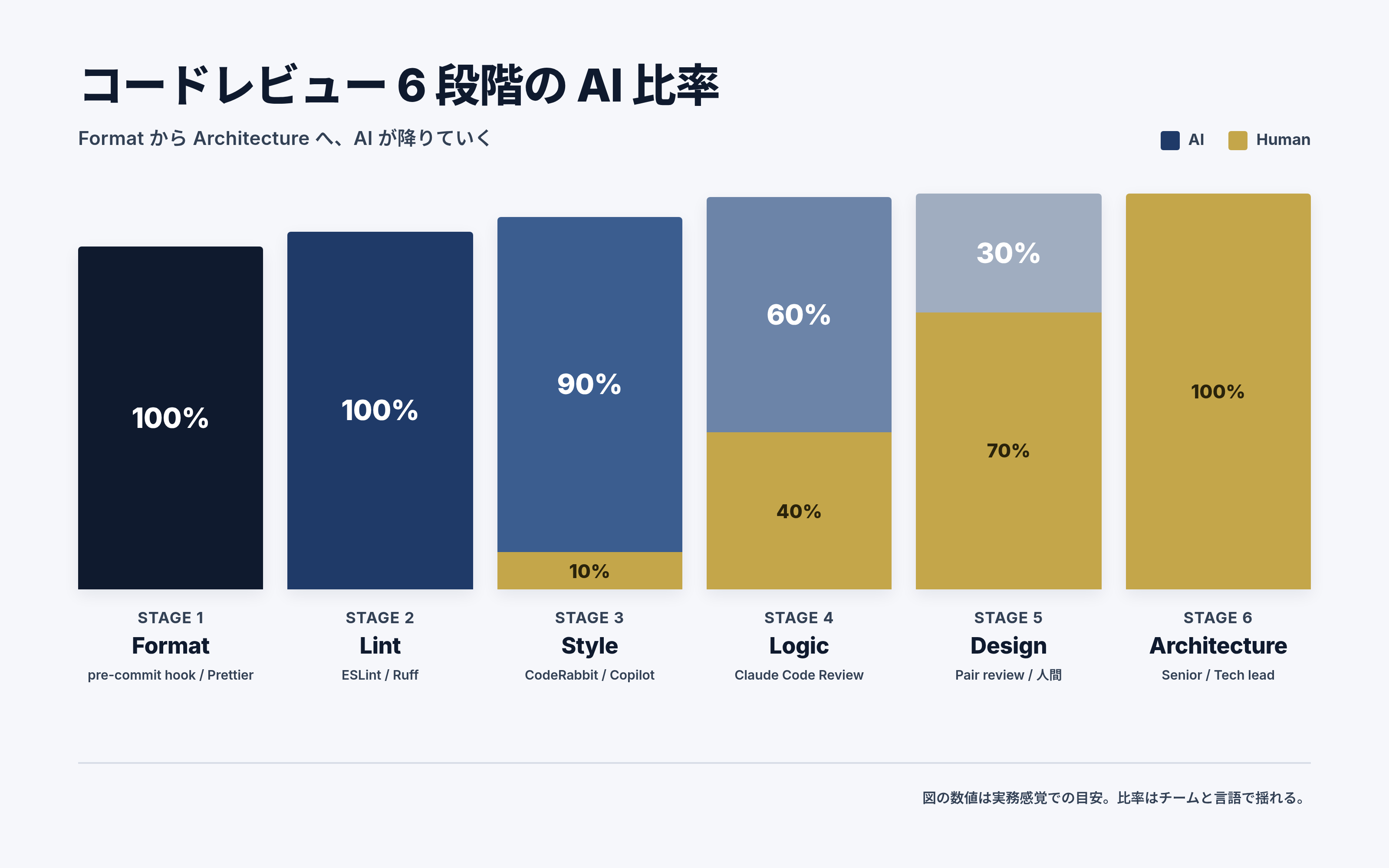
6段階の定義
私が現場で使っている6段階はこうです。AI 比率は実務感覚での目安で、チームや言語によって揺れます。
| 段階 | 対象 | AI比率 | 人間比率 | 主なツール |
|---|---|---|---|---|
| 1 | Format | 100% | 0% | pre-commit hook, Prettier |
| 2 | Lint | 100% | 0% | ESLint, Ruff |
| 3 | Style | 90% | 10% | CodeRabbit, GitHub Copilot |
| 4 | Logic | 60% | 40% | Claude Code Review |
| 5 | Design | 30% | 70% | Pair review |
| 6 | Architecture | 0% | 100% | Senior, Tech lead |
下に行くほど「正解が一意でない」問題になります。Format には正解がありますが、Architecture には正解がありません。AI が降りていくのではなく、 問題の性質が変わっていく のだ、と捉えると整理しやすいです。
段階1: Format(100% AI)
インデント、空白、改行コード、末尾セミコロン。これらは pre-commit hook で全部 AI が処理します。
#!/bin/bash
npx prettier --check . --ignore-unknownここに人間の判断は1ミリも要りません。レビュアーが「インデントが揃ってない」とコメントしているのを見ると、私は心の中で謝りながらツール導入を提案します。本人は品質を守っているつもりですが、消耗しているのはレビュアー本人です。
段階2: Lint(100% AI)
未使用変数、到達不能コード、暗黙的な型変換。静的解析ツールが見つけてくれます。 ESLint、Ruff、 mypy 、 tsc。
Format と Lint は同じ層では?と思うかもしれません。私は分けています。 Format は「見た目」の規約、 Lint は「意味」の規約です。 Format は壊れても動く、 Lint は壊れたら動かない(または将来動かなくなる)。混ぜると、 pre-commit が遅くなったときに「どっちを外すか」の判断ができなくなります。
ここまでが「PR にすら到達させない層」です。私はこの2段階で、毎週30分の指摘時間を構造的にゼロにしました。
段階3: Style(90% AI / 10% 人間)
命名、関数の分割粒度、コメントの過不足、可読性。
ここから AI 比率が下がります。 CodeRabbit と Copilot が得意な領域ですが、 完全には自動化できない理由 があります。
例えば「関数名 getUserData を fetchUser に変えるべきか」は、コードベース全体の命名規則を見ないと判断できません。 CodeRabbit は .coderabbit.yaml でプロジェクト固有のルールを読み込めますが、すべての方針をルール化できるわけではありません。
私のチームでは、 Style の最終承認は人間です。AI が90%の指摘を出し、人間が「この提案は採用、これは却下」と判断します。「面白くいこうぜ」と心の中で唱えながら、却下するときの理由を一行コメントで残すと、次の AI レビューの精度が上がります。
段階4: Logic(60% AI / 40% 人間)
ここが私が3つのバグを通した場所です。
N+1問題、 SQL インジェクション、未処理の例外、明らかなエッジケース。 AI はこのあたりまでは見つけてくれます。 Macroscope のベンチマーク によると、バグ検出精度は Macroscope 48%、 CodeRabbit 46%、 Cursor BugBot 42%、 Greptile 24%。半分以上は見逃すと思っておくのが安全です。
CodeRabbit と Copilot を比較したベンチマーク では、 CodeRabbit が F1 51.5% / recall 52.5% 、 Copilot が F1 44.5% / recall 36.7%。 CodeRabbit のほうが見つけはするのですが、それでも recall は半分強です。「6割見つかれば上等」というのが現状の感覚に近い。
私が通した3バグは全部「ビジネスロジック由来のエッジケース」でした。
- 「空配列が来たら処理スキップ」が仕様だったのに、 AI は「空配列でも処理する」コードを問題なしと判定
- 外部 API のリトライ条件として「 429 のみ」が仕様だったのに、 AI は「 5xx すべてリトライ」を提案
- ページネーション境界で1件ずれる古典的バグを、 AI は「テストが通っているから OK 」と判定
これらは、 AI から見るとコードとして正しい。仕様書を見ていない AI は、コードベース内の整合性しか見られないのです。
Claude Code の /review や /ultra review は複数エージェントで角度を変えて見るので、単一の AI レビューよりは見落としが減ります。それでも仕様判断の最終責任は人間です。 Claude Code 公式ドキュメント も、 logic errors や edge cases は「context of your full codebase」での検出と書いていて、仕様書は射程外です。
私が現場で運用しているルールはシンプルです。 Logic 層で AI が指摘した部分は AI に任せ、 AI が指摘しなかった部分こそ人間が念入りに見る 。 AI のコメント数が多い PR ほど、人間レビューは短く済みます。 AI のコメントがゼロの PR こそ、仕様書を開いて30分かけて読む価値がある。逆説的ですが、これがバグを通さなくなった一番大きな運用変更でした。
段階5: Design(30% AI / 70% 人間)
責務分割、 API の境界、依存関係の方向。
ここからは AI の出る幕が一気に減ります。 「このメソッドは User クラスに置くべきか、別の Service クラスに置くべきか」は、コードベースの設計思想次第です。 AI は既存のパターンを学習はしますが、 「このパターンを増やすべきか減らすべきか」という方向性の判断はできません 。
私が Design 層で AI に期待するのは、せいぜい「この関数は150行あります。分割を検討してください」のような機械的なヒントです。残りの70%は人間がペアレビューで判断します。
ここで効くのは2人レビューです。1人だと「自分の好み」を「設計判断」と取り違える。2人いれば、「これはどっちの設計でも動くね、じゃあ既存パターンに揃えよう」のような対話ができます。信長の野望で軍議をするようなものです。城を守るか打って出るかは、軍議で決まる。
Design 層で私が AI を信用していない別の理由もあります。 AI は学習データの中の「平均的な良い設計」に寄せがちで、 そのコードベース固有の制約を読まない 。例えば「マルチテナント DB なので Service 層は必ず tenant_id を引数で受け取る」というローカルルールは、 AI には伝わりにくい。 path-scoped instructions で頑張れば伝わりますが、ルールが増えるほどメンテナンスコストも上がります。設計の方向性は、コードに先行する暗黙のチーム合意で決まるので、文章化されていないものを AI に読ませるのは原理的に難しい、と私は思っています。
段階6: Architecture(0% AI / 100% 人間)
システム境界、データフロー、認証の責任範囲、デプロイ単位。
ここに AI は一切入れていません。理由は単純で、 アーキテクチャの判断は「正解」ではなく「未来予想」 だからです。3年後にこのシステムがどう成長するか、チームがどう拡大するか、ビジネスがどこにピボットするか。これらの問いに対して、 AI はもっともらしい答えは出せますが、責任を取れません。
GitHub Copilot のドキュメントも、 missing most architectural concerns と公式に書いています。 AI レビューはアーキテクチャ判断を支援しません。
Architecture レビューは、レビューというより「設計会議」です。 PR に対する作業ではなく、 PR の前にやるべき作業です。 ADR(Architecture Decision Record) を書き、テックリードがファシリテートして30分議論する。コードを書く前に方向が決まっていないなら、 PR レビューの段階で揉めても遅い、というのが私の学びです。
具体例で言うと、「認証ロジックを各マイクロサービスに置くか、 API Gateway に集約するか」のような決定は、 PR で揉めると地獄になります。コードが書き終わってから決めると、片方を捨てることになる。事前に ADR で「集約する」と決めておけば、 PR レビューでは「ADR と整合しているか」だけ確認すれば済む。 AI は ADR と整合しているかを機械的にチェックできるので、 ADR を書いた瞬間に、 Stage 6 の一部が Stage 5 や Stage 4 に降りてくるという面白い現象も起きます。文章化することで、 AI 比率が上がるのです。
6段階で「Approveの意味」が変わる
3層モデルのときの Approve は、「フォーマット OK 、 AI OK 、私もざっと見た」の3点セットでした。
6段階で運用し始めてから、私は Approve を出すときに自分に問いかけます。
「私はどの段階まで責任を持ってこの Approve を押しているか?」
Format と Lint は通っている。 Style は AI の指摘に同意した。 Logic は仕様書と照らして3つのエッジケースを確認した。 Design は責務分割に違和感がない。 Architecture は事前の設計会議で議論済み。
このチェックを通った Approve は、3層モデルのときの Approve より重みがあります。逆に、 Logic と Design に不安があるなら、 「Approve しない選択」をしやすくなります。 「とりあえず LGTM 」が出にくくなる構造です。
チーム導入のステップ
いきなり6段階を全部導入しようとすると、たぶん挫折します。私の経験では、こういう順序が現実的です。
- まずStage 1-2を hooks で固める : ここは1日で終わる。即日効果が出る
- Stage 3 に CodeRabbit か Copilot を入れる : Copilot 契約があれば無料。1週間慣らす
- Stage 4 のための仕様書整備 : ここが一番時間がかかる。 AI が見られない「仕様由来のエッジケース」を、まず人間が明文化する
- Stage 5-6 はチーム文化として育てる : ペアレビューと ADR 。仕組み化より習慣化
Stage 4 で詰まったら、私のように本番でバグを3つ通す経験ができます。冗談ではなく、構造的に「 AI が見える範囲」と「人間が見るべき範囲」を分けないと、 Logic 層は AI 任せになります。
「AIに任せて安心」が一番危ない
私がバグを3つ通した本当の理由は、 AI レビューが完璧だと思い込んでいたことではありません。 「AI が見ているから、自分は見なくていい」と無意識に判断していたこと です。
これは認知のショートカットで、 AI レビューを導入するすべてのチームに起きます。Stage 4 の Logic 層が一番危ない理由は、 AI のカバー率が60%という「中途半端な高さ」だからです。 0%なら人間が全部見る。 100%なら AI に任せる。60%は「7割ぐらいは大丈夫だろう」という油断を生みます。
6段階に分けた一番の効用は、 Stage 4 が「中間ゾーン」だと可視化されたことです。中間ゾーンは、人間の集中力が一番要る場所だと分かるようになりました。
まとめ
- コードレビューは Format / Lint / Style / Logic / Design / Architecture の6段階に分けられる
- AI 比率は Format 100% から Architecture 0% へ段階的に下がる
- 一番危ないのは Stage 4 の Logic 層。 AI カバー率60%が油断を生む
- Approve を押す前に「どの段階まで責任を持っているか」を自問する
- Stage 1-2 から導入し、 Stage 4 のための仕様書整備に一番時間を投資する
3層モデルが「誰が何を見るか」の設計図なら、6段階は「どこに集中力を残すか」の解像度です。 AI レビューが当たり前になった今、 境界線をどこで引くかは、各チームが自分で決めるべきこと だと思います。
3層モデルの全体像を、12枚のスライドに
6段階の解像度の土台にある3層モデル(hooks・AI・人間)を、レビュー仕組み化の全体像として12枚にまとめました。スライドだけでも流れがつかめます。
この記事は役に立ちましたか?