LLMO対応はテストしないと静かに壊れる:AIクローラーの可読性をPlaywrightでCI検証する
去年の私は、LLMO対応を済ませて満足していました。robots.txtに13種類のAIクローラーの個別ルールを書き、llms.txtを整え、JSON-LDを各ページに埋め込み、URL.mdエンドポイントも用意しました。やりきった気になって、しばらく見ていませんでした。
3ヶ月後、ふと自分のサイトのllms.txtを開いたら、404でした。リニューアルのときにビルド設定を変えて、出力されなくなっていたのです。誰にも気づかれず、AIクローラーにも気づかれず、静かに壊れていました。LLMO対応というのは、設定して終わりではなかったのです。SEOとまったく同じでした。
この記事は「設定編」ではなく「テスト編」です
先に線引きをしておきます。LLMO対応の記事はすでにたくさんあります。私自身、robots.txtの書き方、llms.txtの監査、JSON-LDの設計、引用率の効果測定について書いてきました。それらは全部「設定する」「監査する」「測る」話です。
この記事は別の層を扱います。設定した内容が壊れていないかを、CIで継続的にテストする 実装です。robots.txtの記事が「13クローラーの個別ルールを書いた」という設定編だとすれば、この記事は「その設定をPlaywrightで守れているか検証する」テスト編です。一度書いたら、あとは更新のたびに勝手に見張ってくれる仕組みを作ります。
なぜこれが必要か。理由は単純で、LLMO対応は普通のコードと違って、壊れても画面が赤くならないからです。テストがなければ、壊れたことに気づくのは数ヶ月後、流入が落ちてからです。
2026年のAIクローラーは見張る価値が上がっている
放置していい話だったなら、ここまで力を入れません。状況が変わりました。
GEOリサーチャーのZach Lukerによる解説によると、AI検索経由の訪問は前年比42.8%、ChatGPTからの流入は前年比52%伸びています。AnthropicはボットをClaudeBot(モデル訓練)、Claude-SearchBot(検索インデックス)、Claude-User(ユーザー起点の取得)の3つに分離していて、それぞれrobots.txtの記述を厳密に見ます。OpenAIも同様に、GPTBot(訓練)とOAI-SearchBot(検索取得)で役割が分かれています。
つまり「AIクローラーを許可する」という一文では足りなくなりました。どのボットに何を許すかを個別に書く時代です。記述が増えれば増えるほど、壊れる箇所も増えます。AI経由の流入が前年比で伸び続けている今、せっかく書いた許可設定が次のデプロイで消えていたら、その伸びをまるごと取りこぼすことになります。
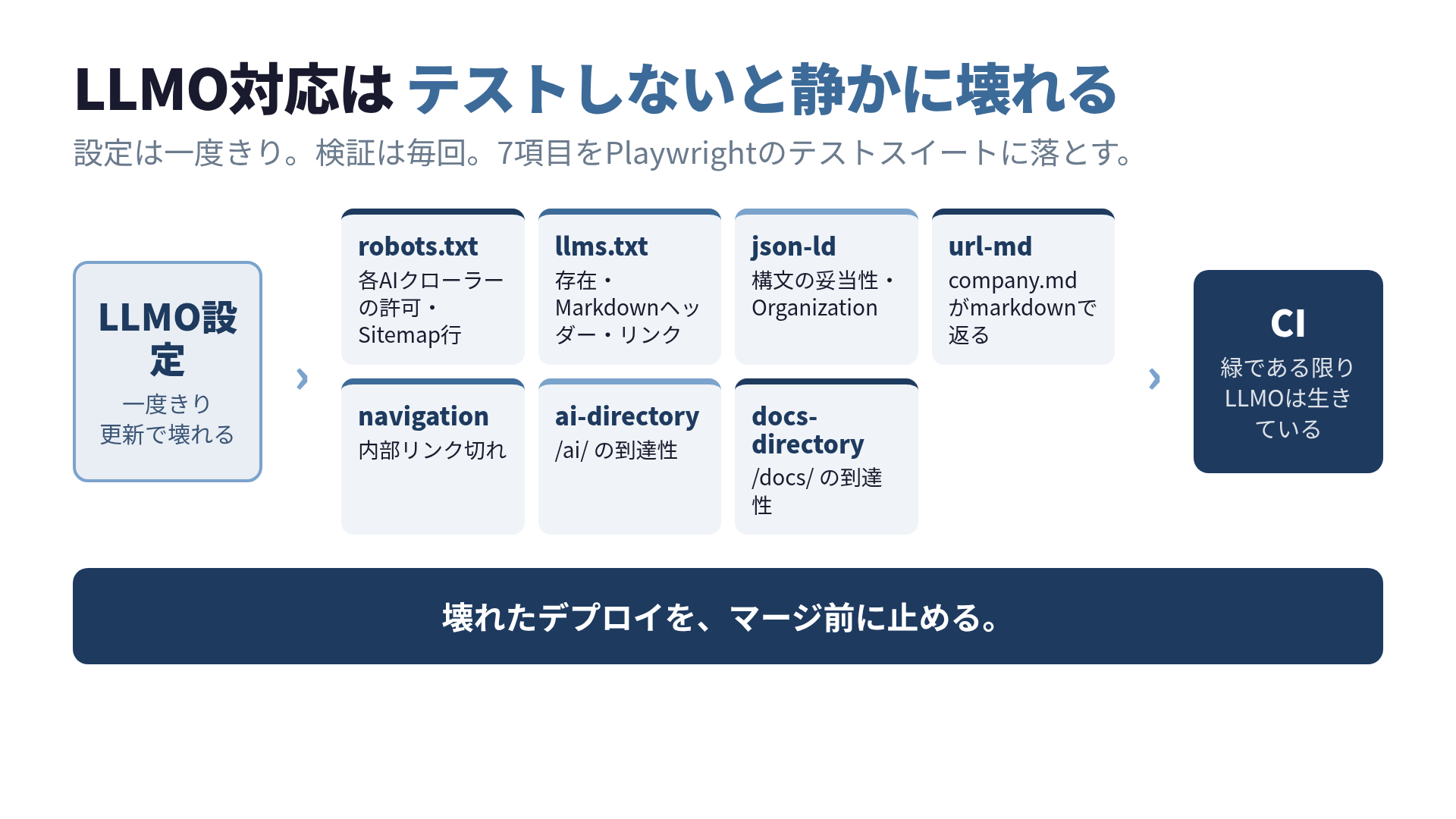
何をテストするのか:検証項目の棚卸し
実装に入る前に、そもそも何を検証すべきかを決めます。ここで便利なのが、LLMO対応の検証項目をフレームワーク化したllmoframework.comです。検証すべき要素を構造化してくれているので、テストケースの設計図として使えます。
私のサイトでテスト対象にしているのは、次の7つです。
- robots.txt: 各AIクローラーの許可記述、Sitemap行
- llms.txt と llms-full.txt: 存在、Markdownヘッダー、/ai/ と /docs/ へのリンク
- JSON-LD: 構文の妥当性、Organizationスキーマの必須フィールド
- URL.md パターン: company.md などがtext/markdownで返るか
- ナビゲーション: 内部リンク切れ
- /ai/ ディレクトリ: AI向けコンテンツの到達性
- /docs/ ディレクトリ: ドキュメントの到達性
この7項目を、Playwrightのテストスイートに落とします。
Playwrightで書く
Playwrightを選ぶ理由は、request でHTTPレスポンスを直接叩けて、page でJSレンダリング後のDOMも検査できるからです。robots.txtのような静的ファイルも、JSON-LDのような描画後の要素も、同じ枠組みで検証できます。
テストの置き場所はこう分けています。
tests/
├── helpers.ts ← 共通ヘルパー
└── llmo/
├── robots-txt.spec.ts ← robots.txt検証
├── llms-txt.spec.ts ← llms.txt検証
├── json-ld.spec.ts ← JSON-LD検証
├── url-md.spec.ts ← URL.mdパターン検証
├── navigation.spec.ts ← リンク切れ検証
├── ai-directory.spec.ts ← /ai/ディレクトリ検証
└── docs-directory.spec.ts ← /docs/ディレクトリ検証robots.txtのテストはこうなります。私が3ヶ月放置して壊した、まさにあの部分です。
import { test, expect } from '@playwright/test';
test.describe('robots.txt', () => {
test('robots.txt が 200 で返る', async ({ request }) => {
const res = await request.get('/robots.txt');
expect(res.status()).toBe(200);
});
test('GPTBot が許可されている', async ({ request }) => {
const res = await request.get('/robots.txt');
const text = await res.text();
expect(text).toContain('GPTBot');
});
test('ClaudeBot が許可されている', async ({ request }) => {
const res = await request.get('/robots.txt');
const text = await res.text();
expect(text).toContain('ClaudeBot');
});
test('Sitemap 行が含まれている', async ({ request }) => {
const res = await request.get('/robots.txt');
const text = await res.text();
expect(text).toContain('Sitemap:');
});
});llms.txtのテストでは、ファイルの存在だけでなく中身も見ます。空っぽの200を返しているケースを拾うためです。
test.describe('llms.txt', () => {
test('/llms.txt が存在し Markdownヘッダーを持つ', async ({ request }) => {
const res = await request.get('/llms.txt');
expect(res.status()).toBe(200);
const text = await res.text();
expect(text).toContain('# ');
});
test('llms.txt に /ai/ と /docs/ へのリンクがある', async ({ request }) => {
const res = await request.get('/llms.txt');
const text = await res.text();
expect(text).toContain('/ai/');
expect(text).toContain('/docs/');
});
});JSON-LDは、構文エラーが一番混入しやすい場所です。JSON.parse に通すだけで、壊れた構造化データを検出できます。
test.describe('JSON-LD 構造化データ', () => {
test('トップページのJSON-LDがパースでき Organization を含む', async ({ page }) => {
await page.goto('/');
const jsonLd = await page
.locator('script[type="application/ld+json"]')
.textContent();
const data = JSON.parse(jsonLd!);
const org = data.find((d: any) => d['@type'] === 'Organization');
expect(org?.name).toBeTruthy();
expect(org?.url).toBeTruthy();
});
});設定は playwright.config.ts でプレビューサーバーを立てるだけです。
import { defineConfig } from '@playwright/test';
export default defineConfig({
webServer: {
command: 'npm run preview',
port: 4321,
reuseExistingServer: true,
},
use: { baseURL: 'http://localhost:4321' },
});npx playwright test を走らせると、私の環境では33テストが通ります。この33という数字が、デプロイのたびに緑であり続けることが、LLMO対応が生きている証拠になります。正直に言うと、最初に書いたときは5つ落ちました。3ヶ月放置のツケです。
CIに組み込んで、二度と放置しない
ローカルで通るだけでは、また私のように放置して壊します。GitHub Actionsに載せて、PRごとに走らせます。
name: LLMO Tests
on:
pull_request:
push:
branches: [main]
jobs:
llmo:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '22'
- run: npm ci
- run: npx playwright install --with-deps chromium
- run: npx playwright test tests/llmo/これで、llms.txtを404にするようなデプロイはマージ前に止まります。私が3ヶ月気づかなかった壊れ方は、もう物理的に起きません。テストが赤くなって、マージできなくなるからです。
LLMO対応はSEOと同じで、問われるのは「やったかどうか」ではなく「今この瞬間、生きているかどうか」です。設定は一度きりですが、検証は毎回です。手で毎回確認するのは続きません。続かないことは、続く仕組みに変えるしかありません。
まとめ
- LLMO対応は設定して終わりではなく、サイト更新で静かに壊れる。画面が赤くならないぶん、SEOより気づきにくい
- robots.txtの設定が複雑化している今(ClaudeBotの3分離、GPTBotとOAI-SearchBotの役割分担)、壊れる箇所も増えている
- llmoframework.comで検証項目を棚卸しし、7項目をPlaywrightのテストスイートに落とす
requestで静的ファイル、pageで描画後のJSON-LDを同じ枠組みで検証できる- GitHub Actionsに載せて、壊れたデプロイをマージ前に止める。人の意志に頼らず、仕組みで放置を防ぐ
llms.txtの書き方、最小限のJSON-LDパターン、AI引用率の測り方そのものは、別の本にまとめています。SEOを知っているエンジニアが最短でAIに引用されるための実装ガイドです。設定を固めてから、この記事のテストで守ってください: LLMO Quickstart
この記事は役に立ちましたか?