Pluguei o Claude num MCP de Chaos. Matou staging 4 vezes pra achar um bug que ignorávamos há 6 meses.
A Steadybit lançou em meados de 2025 o que é descrito como o primeiro MCP server de Chaos Engineering do mercado. Pluguei o Claude Code nele e pedi, numa frase só, pra desenhar experimentos de resiliência do payment-service sob pressão de connection pool. O Claude propôs quatro. Três voltaram verdes, sem violar SLO. O quarto derrubou o staging inteiro. Quando fui rastrear, não era bug fabricado por teste. Era um padrão real de produção que aparecia nos logs há 6 meses, que ninguém tinha conseguido reproduzir: esgotamento de pool → tempestade de retry → rate limiter dando self-DoS.
Aviso curto antes de seguir: todo experimento rodou em staging, com cadeado duplo (## Chaos Rules no CLAUDE.md proibindo alvos de produção + hook PreToolUse com exit 2 em --env=production). Mostro os dois no final.
Hoje conto a corrida, o bug e os 3 guardrails que agora exijo antes de qualquer IA desenhar experimento de chaos.

Como pluguei o Claude no Steadybit MCP, em um parágrafo
A Steadybit anunciou em 18 de junho de 2025 o que descreve como o primeiro MCP server pra Chaos Engineering (Steadybit news / BusinessWire 2025-06-30). MCP é o Model Context Protocol aberto que a Anthropic publicou no fim de 2024: uma forma padronizada de um cliente LLM (Claude, Gemini, ChatGPT) chamar uma ferramenta externa com tipos estruturados em vez de raspar texto. O MCP server da Steadybit expõe o catálogo de experimentos, resultados passados, post-mortems, e uma ferramenta de “desenhar novo experimento”. Você pluga Claude Code ou Claude Desktop, aponta os dois pro mesmo contexto Kubernetes de staging, e escreve "desenha um experimento de stress de connection pool pro payment-service" no terminal. Volta uma spec parametrizada, pronta pra aprovar.
Setup é encanamento. A pergunta interessante é o que sai do outro lado depois que você abre a torneira.
AI-driven chaos em 2026: os 4 players que comparei
Antes de soltar a corrida, queria saber o que mais existia no mercado. Hoje existem 4 players que importam, e cada um puxa uma alavanca diferente.
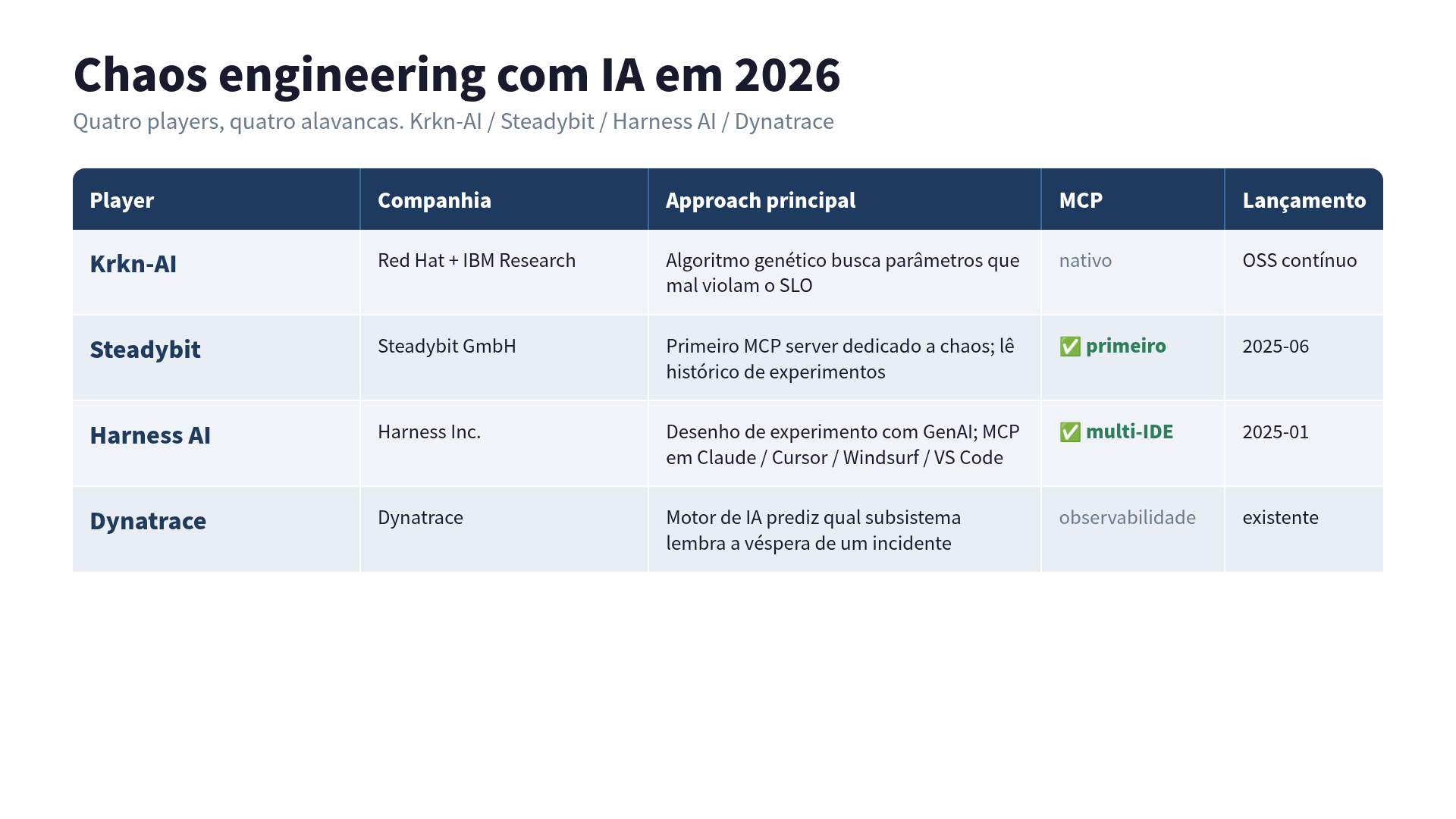
Krkn-AI é o framework open-source que Red Hat e IBM Research desenvolvem em conjunto. A ideia é colocar um algoritmo genético no comando da busca: gera parâmetros de experimento, avalia cada um contra os seus SLOs (latência, taxa de erro, disponibilidade), pontua, evolui as melhores combinações, repete. O alvo são os experimentos “que mal violam”: aqueles que derrubam um SLO de 99,9% pra 99,85%, não os que quebram tudo de cara. São esses os bugs perigosos, difíceis de reproduzir. O writeup da Red Hat tá em Red Hat Developer, e o código é krkn-chaos/krkn-ai.
Harness AI lançou recursos de chaos engineering com GenAI em janeiro de 2025 e depois adicionou ferramentas MCP que funcionam com Claude Desktop, Windsurf, Cursor e VS Code. A proposta é “descreve o que quer em português, recebe um experimento parametrizado, roda do chat”. Se você já mora no ecossistema Harness, é o caminho com a curva de aprendizado mais baixa.
Steadybit foi o que usei aqui, a primeira a lançar um MCP server dedicado pra chaos, em junho de 2025. O diferencial é o acesso ao histórico de experimentos: o LLM não só desenha experimento novo, ele lê seus runs passados e post-mortems, e fundamenta as sugestões na sua história específica de incidente.
Dynatrace joga ao contrário. O motor de IA aprende o comportamento normal do sistema e prediz quando um padrão atual lembra a véspera de algum incidente passado. Em vez de você propor uma hipótese pra testar, a plataforma te diz qual subsistema merece atenção de chaos a seguir.
Se você roda um experimento por trimestre, o ângulo de predição do Dynatrace é exagero. Se você tem time de pesquisa e Kubernetes, o algoritmo genético do Krkn-AI é o mais fundo. Se você já está em Harness ou Steadybit, o MCP tira o imposto do dashboard. Os 4 não competem de verdade: empilham em camadas.
Os 4 experimentos que o Claude propôs
Voltando à corrida real. O prompt foi uma frase. A resposta foi uma lista numerada com 4 experimentos, cada um com serviço-alvo, tipo de falha, magnitude, duração, SLO de rollback e blast radius. Vou parafrasear em vez de colar literal, porque a spec real era YAML e a estrutura legível pelo LLM não é a parte interessante. O desenho do experimento é.
Experimento 1: pool a 30% menor, 3 minutos, um pod. Corta o max da connection pool de 100 pra 70 numa réplica só. SLO gate: taxa de erro abaixo de 1%. Resultado: verde. Latência subiu uns 12%, mas erro ficou em 0,2%, bem dentro do limite. As outras réplicas absorveram tráfego. É o experimento que um SRE humano propõe primeiro.
Experimento 2: pool 50% menor com retries default, 3 minutos, dois pods. Mesma falha, magnitude mais funda, duas réplicas em vez de uma, com retry-on-failure da biblioteca-cliente ligado. SLO gate: erro abaixo de 1%, p99 abaixo de 800 ms. Resultado: verde de novo. Latência foi pra ~640 ms p99, erro 0,4%. Dentro do limite. A camada de retry absorveu a pressão do pool.
Experimento 3: pool 70% menor com timeout encurtado, 3 minutos, dois pods. Agora o timeout caiu de 5 s pra 1,5 s enquanto a pool foi pra 30. Hipótese: sob pressão alta, timeout curto ajuda liberando conexão mais rápido, ou atrapalha cortando requisição no meio do trabalho? Resultado: ainda verde, surpreendentemente. Erro 0,7%, p99 caiu pra ~520 ms porque chamadas lentas eram cortadas cedo. Quase parei aqui. Três verdes em sequência davam cara de prova de resiliência.
Experimento 4: pool 90% menor com retry sem limite, 5 minutos, três pods. Esse foi. Pool pra 10 conexões por pod, orçamento de retry praticamente infinito (default desse cliente, que não tinha sido sobrescrito no config), três réplicas atingidas ao mesmo tempo. SLO gate: erro abaixo de 1%. Resultado: não verde. Nos primeiros 90 segundos, taxa de erro saiu de 0,5% pra 23% em linha vertical, p99 saiu de 200 ms pra 14 segundos, e o staging ficou inalcançável do gateway upstream. A Steadybit fez auto-rollback na violação de 1% do SLO, mas a essa altura o estrago já era um serviço completamente travado.
Os três primeiros verdes não eram prova de resiliência. Eram prova de que o blast radius era pequeno o bastante pra ser absorvido. No quarto, alarguei o raio só um pouco além do que o sistema absorvia, e a patologia que tava dormindo embaixo veio à tona.
Escrevi no Slack que o incidente em staging era “planejado”. O on-call não riu. Apontou que o canal de post-mortem ainda tava com o pin do incidente do trimestre passado. Deixei ele atualizar o pin com o de hoje.
O bug que a gente tinha ignorado por 6 meses
Eu esperava que o problema do staging fosse uma esquisitice de staging: env var diferente, sidecar estranho, timing que não reproduz em prod. Rastrei mesmo assim. A cadeia tinha 3 peças, cada uma sozinha documentada e tranquila, e composta virou doença.
Peça 1: esgotamento do connection pool. Pool no máximo em 10, três pods sob tráfego normal. Toda requisição que precisava de conexão nova esperava ou falhava. Padrão. Sem surpresa.
Peça 2: retries sem limite no serviço que chamava. O serviço upstream que chamava o payment-service tinha retry ligado, com limite só por tempo-por-tentativa, não por número de tentativas. Quando o payment-service começou a devolver erro de pool exaurido, o caller fez retry. Cada retry abria uma conexão TCP nova, que entrava na fila do pool, que dava timeout, que disparava outro retry. Três retries viraram nove, viraram 27. Em segundos, a concorrência de saída do caller tava uma ordem de magnitude acima da linha de base.
Peça 3: o rate limiter do próprio caller. Essa peça custou meia hora pra eu enxergar. O caller tinha um rate limiter de auto-proteção na rota outbound: “não deixa esse serviço fazer mais de N requisições por segundo pra nenhum downstream”. Em operação normal, N nunca chegava perto. Na tempestade de retry, o caller passou do próprio rate limiter de saída e começou a rejeitar os próprios retries. A aplicação interpretou a rejeição como falha de downstream e fez ainda mais retry. O caller tava se DoSando, usando o próprio rate limiter como arma. O payment-service downstream não recuperava, porque tráfego novo não conseguia atravessar o self-DoS do caller pra avisar que o pool já tava livre.
Voltei nos logs de produção dos últimos 6 meses procurando a assinatura de “rate limiter rejeitando retry no outbound” desse serviço. Achei 11 eventos. Cada um durava de 4 a 90 segundos, cada um se auto-resolvia antes que alguém terminasse de abrir o Grafana, e cada um caía no balde de “transiente, não acionável”. É exatamente o padrão que a fitness function do Krkn-AI tenta caçar: falha que mora logo depois da fronteira do SLO, curta o bastante pra humano desistir, real o bastante pra importar.
A correção não foi glamourosa. Limitamos os retries em 2 com jitter, mudamos o rate limiter de saída pra se comportar como circuit breaker em vez de rejeição dura, e adicionamos uma métrica pra essa sequência específica (pool-exhaust → spike de retry → rejeição-outbound-no-retry) pra que a próxima vez acorde alguém em vez de se curar invisível.
Os 3 guardrails que agora exijo
Sou a pessoa que ano passado escreveu um post sobre deixar o Claude solto por 24 horas. Não sou anti-autonomia. Mesmo assim, “IA desenha chaos” sem guardrail foi o jeito mais rápido que já encontrei de matar staging. Três coisas entram em todo projeto antes do MCP server chegar perto de qualquer ambiente real.
Guardrail 1: CLAUDE.md fica com a política. Bloco curto, menos de 20 linhas, que nomeia as proibições e os SLO gates.
## Chaos Rules
- Experimentos de chaos rodam só em staging. Produção é proibida como alvo,
incluindo qualquer cluster, namespace ou serviço marcado production=true.
- Todo experimento declara SLO gate (taxa de erro, latência, disponibilidade)
que faz auto-rollback se violado.
- Blast radius é escalado: começa em 10% dos pods, sobe pra 25%, depois 50%.
Pular um estágio exige aprovação humana no prompt.
- Três experimentos verdes em sequência não declaram resiliência. Proponha
blast radius maior ou tipo de falha novo antes de parar.
## Chaos Workflow
1. Confirmar que o ambiente alvo é staging. Recusar caso contrário.
2. Propor experimento com SLO gate, blast radius e rollback declarados.
3. Esperar aprovação humana no prompt antes de chamar a tool de run do MCP.
4. Streamar métricas durante a corrida. Em violação de SLO, chamar rollback.
5. Depois da corrida, escrever um post-mortem de um parágrafo com o resultado.A parte difícil do CLAUDE.md é manter ele curto o suficiente pra carregar em contexto todo turno. A diretriz da Anthropic é ficar abaixo de mais ou menos 100-150 linhas. Gastar 16 dessas linhas em regras de chaos é um bom negócio pra não matar o staging no primeiro dia.
Guardrail 2: hooks PreToolUse forçam a política. CLAUDE.md é o cérebro. Hooks são o reflexo. O cérebro pode ser ignorado sob carga. O reflexo não.
{
"hooks": {
"PreToolUse": [
{
"matcher": "mcp__steadybit__run_experiment",
"hooks": [
{
"type": "command",
"command": "node ~/.claude/hooks/block-prod-chaos.js"
}
]
}
]
}
}O script de bloqueio inspeciona a spec do experimento atrás de qualquer marcador de produção. Se env: production, cluster: prod ou namespace: prod-* aparecer em qualquer lugar do payload, ele escreve o motivo no stderr e dá exit 2 pra barrar a chamada. Esse trecho me salvou pelo menos uma vez. O LLM, no meio da conversa, sugeriu prestativamente promover um experimento “só pra confirmar em prod”. O hook disse não antes do MCP server ver.
O mesmo hook ainda confere se o SLO gate foi declarado com valor numérico e se o estágio do blast radius é igual ao estágio anterior +1. Spec só com número mágico? Bloqueado. Pular o estágio 2 do blast radius? Bloqueado. O reflexo tem o mesmo formato da regra.
Guardrail 3: o próprio MCP server fica com o cadeado de SLO. A terceira camada é do lado da plataforma. Na Steadybit (e da mesma forma no Harness, no Krkn e companhia), a configuração do experimento recebe um predicado rollback_on que a própria plataforma avalia em tempo real nas métricas. Se a taxa de erro passar de 1% por 30 segundos, a plataforma para o experimento independente do que o LLM ou o hook local fizerem. É a única das três camadas que sobrevive caso o LLM e o agente local estejam comprometidos ao mesmo tempo. Também é a que mais time esquece, porque exige opinião sobre seus SLOs que ninguém quer digitar em YAML. Digite mesmo assim.
Um teste útil: pega alguém aleatório do time, entrega o CLAUDE.md e o arquivo de hooks, e pergunta “com má-fé, daria pra você desenhar um experimento que bate em prod?”. Se a resposta for “dá, editando o CLAUDE.md”, o cadeado do SLO da plataforma é quem pega. Se a resposta for “dá, removendo o hook”, o cadeado do SLO da plataforma é quem pega. As três camadas não são redundantes: falham de jeitos diferentes.
A separação em três papéis que descrevi num post anterior (observer, strategist, marketer) mapeia direto pra chaos: o CLAUDE.md é o strategist (define política), os hooks são o observer (pegam o que acontece), o MCP server é o executor sob os dois. Manter as camadas separadas é o que impede o agente de IA de virar os três sem querer.
Chaos Engineering 2.0: as 4 correntes que convergem
Puxando a câmera pra trás, tem um paper de review de 2024 chamado Chaos Engineering 2.0: A Review of AI-Driven, Policy-Guided Resilience for Multi-Cloud Systems (página do journal) que defende três pilares pra stack moderna: planejadores com IA que desenham experimentos, injeção em nível de service mesh que não exige mudar código de aplicação, e guardrails de política que forçam disciplina de blast radius e SLO. O mesmo paper anota que 89% das organizações pesquisadas hoje rodam multi-cloud, que é o ambiente onde esses modos de falha (drift de DNS entre clouds, ciclo de vida de token IAM diferente, rate limiter local de região) moram de verdade.
Mais recente, o paper arxiv ChaosEater (2025) dá o próximo passo: ciclo de chaos completamente orquestrado por LLM, onde o modelo assume desenho, execução e análise dos experimentos sob guardrails de política. É a mesma direção que os quatro produtos acima estão andando, vista do lado da pesquisa.
Quatro correntes convergem (chaos engineering, observabilidade, IA / LLMs, plataforma), e isso não é slide de marketing. É o workflow real que o meu acidente de staging tava dentro. O chaos engineering forneceu o experimento. A observabilidade forneceu o stream de métrica que pegou a violação de SLO em 90 segundos. O LLM forneceu o desenho do experimento e, depois, ajudou a ler a cadeia de log que prendeu o bug de produção. A engenharia de plataforma (Steadybit + hooks + CLAUDE.md) manteve o blast radius fora da produção.
Tira qualquer uma das quatro e a história termina diferente. Sem LLM, ninguém do time teria proposto o experimento 4. Parecia obviamente irresponsável. Sem observabilidade, a violação demora minutos pra ser notada. Sem guardrail de política, “vamos confirmar em prod” acontece de verdade. Sem chaos como prática deliberada, o bug fica invisível mais 6 meses.
R$ por um dia
Pra dar concretude: staging fora do ar por umas 2 horas (incluindo investigação inicial e o post-mortem rápido) custou uns 5 engenheiros de plantão × 2h × ~R$ 100/h ≈ R$ 1.000 de tempo direto, mais o gap de outras prioridades. Aceitável. Se essa mesma cadeia tivesse acordado em produção primeiro (pool exaurido em pico, retry storm rodando em todo cliente, rate limiter dando self-DoS), era violação de SLA com cliente PIX + perda de receita de pagamentos por minuto. Pra um payment-service de fintech / e-commerce do tamanho médio, esse minuto custa por aí dos R$ 100.000 de impacto total, considerando reembolsos, ressarcimento e o cabo de comunicação com clientes que ninguém quer pegar de novo. O chaos pago R$ 1.000 pra descobrir o que evitou um incidente de R$ 100.000. É o trade que justifica.
O que eu diria pra quem vai tentar isso semana que vem
Se você quer tentar a mesma coisa sem derrubar o próprio staging às 23h, vai aqui o que eu faria diferente com retrovisor.
Comece só com o experimento 1, em um único namespace, com o blast radius travado em 10% dos pods. Trate o primeiro verde como sinal de alargar o blast radius, não de declarar vitória. O experimento interessante é o que vem logo depois do ponto onde o sistema consegue absorver.
Escreve o CLAUDE.md e os hooks antes de plugar o MCP server. Não depois, não em paralelo, antes. A tentação quando você ganha brinquedo novo é brincar por uma hora e adicionar guardrail depois. Essa hora é quando o staging morre. Também é a hora em que você tem menos paciência pra escrever regra.
Mantém os prompts pós-corrida curtos. “Resume o que falhou, qual SLO violou, e a causa raiz mais provável” já dá. Prompt longo depois de violação de SLO puxa o LLM pra modo narrativa, que é o modo errado. Você quer o LLM em modo evidência, não em modo história.
Leva o hábito de post-mortem do chaos pro AI-coding em geral. Esse post existe porque eu tinha uma página de notas do incidente de 90 segundos, no mesmo formato dos nossos docs de incidente normais. Sem essa página, eu tava escrevendo um post de vibe. Com ela, eu tenho um parágrafo por peça de evidência e uma correção que entrou em prod na mesma semana.
A IA desenha chaos mais rápido que qualquer SRE com quem já trabalhei. Sem os três guardrails, mata staging mais rápido também. Coloca os três, e você ganha a versão em que o LLM acha o bug que você tava perdendo há meio ano, e o on-call do final de semana fica com o final de semana.
O panorama completo (Krkn-AI / Harness / Steadybit / Dynatrace, Chaos Engineering 2.0, e como rodar chaos em produção sem virar manchete) virou um livro de 14 capítulos: Chaos Engineering: Guia Prático para Sistemas Distribuídos Modernos (atualmente em desenvolvimento).
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?