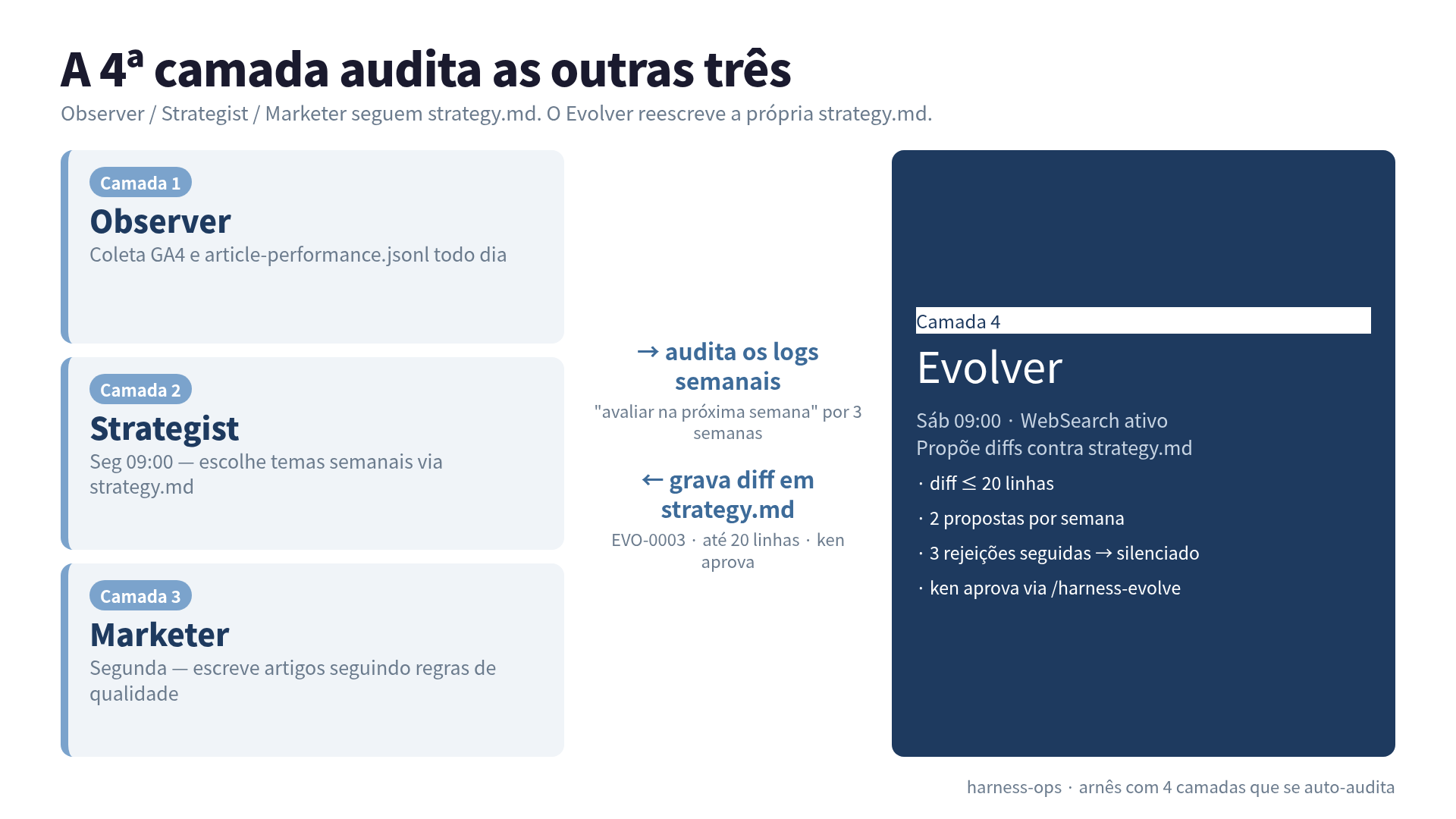
Adicionei um 4º agente que audita meus outros agentes. Ele pegou meu Strategist enrolando há 3 semanas.
Montei um arnês de agente em 3 camadas e chamei isso de “autônomo”. Observer coleta dados. Strategist escolhe os temas da semana. Marketer escreve os artigos. Os três seguem o strategy.md, o arquivo onde estão as minhas regras. Toda segunda 09
Aí eu li meus próprios logs do Strategist de três semanas seguidas e vi uma coisa. O mesmo critério de saída — “se a taxa de Reaction ficar abaixo de 1% por 4 semanas seguidas, revisar a estratégia” — estava sendo postergado havia três semanas. Toda semana o Strategist escrevia “dados insuficientes, observar na próxima semana” e seguia em frente. A regra existia. Os dados existiam. A regra nunca disparou.
O arnês de 3 camadas não pega esse tipo de bug porque os 3 agentes estão fazendo exatamente o que strategy.md mandou eles fazerem. O bug fica na própria regra, e nenhuma camada do arnês tinha como tarefa olhar para as regras.
Adicionei uma 4ª camada chamada Evolver. Na primeira proposta de verdade, ela mandou um diff exatamente contra a regra atrás da qual meu Strategist estava se escondendo.
“Autônomo” era só nome bonito
A arquitetura que eu chamava de autônoma era assim. Observer roda todo dia e despeja números do GA4 em article-performance.jsonl. Strategist roda toda segunda de manhã, lê o strategy.md e escolhe 5 temas para a semana. Marketer transforma cada tema em artigo e empilha na fila de publicação. Três papéis, três crons, comportamento previsível.
O truque que deixou esse pipeline rápido foi eu ter tirado o WebSearch do Strategist de propósito. Strategist com WebSearch ficava 20 minutos perdido em cada rodada e começava a escolher temas que combinavam com notícia do dia em vez de combinarem com meu acervo real de conteúdo. Tirei WebSearch, o ciclo caiu de 20 para 3 minutos. Já escrevi sobre isso em outro lugar. Aquele post era sobre deixar o Strategist mais rápido. Esse aqui é sobre deixar ele prestar contas.
O que nenhuma das três camadas conseguia fazer era reescrever strategy.md. Elas leem toda segunda e obedecem. Se a regra estiver errada, elas obedecem a uma regra errada. A única forma de mudar a regra era eu, humano, notar na revisão semanal. E eu era o gargalo. Eu não estava olhando para os critérios de saída havia pelo menos 3 semanas.
Como a enrolação aparecia nos logs
Vou citar meus próprios logs do Strategist porque o padrão fica mais honesto quando você vê o original.
Log de 3 semanas atrás:
Reaction continua em 0% na maioria dos artigos. Estratégia de título já mudou para primeira pessoa e enquadramento numérico. Quatro semanas seguidas abaixo de 1% justifica revisão de estratégia (atualmente 3 semanas seguidas em observação, decisão na próxima semana).
Log da semana seguinte:
Taxa de Reaction ainda não chegou a 4 semanas seguidas abaixo de 1%, mas dados de tendência semanal estão insuficientes. Observar na próxima semana.
O modo de falha está inteiro nessas duas frases. A regra dizia “4 semanas seguidas”. O Strategist tinha 3 semanas seguidas de dados abaixo de 1%. Em vez de tratar a semana 4 como semana de decisão, ele ficou descrevendo a situação como “ainda em observação” e o relógio nunca andava. O critério de saída tinha sido escrito de um jeito que dava para postergar indefinidamente.
Quando eu mesmo calculei os números a partir de article-performance.jsonl, a foto era pior. Em 24 artigos publicados nas últimas 4 semanas: 812 views, 4 reactions, 7 comments. Reaction: 0.49%. Metade do limite. Engagement (reactions + comments): 1.35%. A regra devia ter disparado há semanas. Não disparou porque não havia, em lugar nenhum do arnês, uma camada cuja tarefa fosse perguntar “essa regra está funcionando mesmo?”.
O 4º cron: Evolver
Adicionei um 4º cron. Roda sábado 09
, em horário separado da cadeia Observer/Strategist/Marketer da segunda. Diferente das três outras, ele tem WebSearch habilitado. A tarefa dele é ler ostrategy.md, ler os logs de decisão das últimas semanas e propor diffs contra o strategy.md. Escrever artigo fica com as outras três camadas.
Cada proposta é um arquivo: domains/<name>/data/evolution/EVO-NNNN.md. O Evolver preenche 5 seções.
- Observação — o que viu nos dados
- Proposta — mudança de regra em prosa
- Embasamento — dados internos e referências externas
- Impacto esperado — o que deve melhorar com a aplicação
- diff — bloco
```diffliteral contrastrategy.md
O bloco diff é a parte que sustenta tudo. O Evolver vai além de sugestão em português: escreve o patch exato que entraria no repositório. Um CLI pequeno chamado harness-evolve.sh sabe extrair o bloco, rodar git apply --check e commitar. Nenhum LLM participa do passo de aplicar. LLM propõe, shell aplica.
Essa separação é proposital. Proposta é criativa. Aplicação é mecânica. Quando o passo de aplicar é mecânico, dá para confiar que ou ele vai dar certo limpo ou vai falhar gritando. Não tem “o agente tentou aplicar o patch e aconteceu uma coisa estranha no meio”.
Stack mínimo (shell + cron + claude -p + flock)
Para quem quer testar no fim de semana sem instalar framework Python:
# crontab
0 9 * * 6 /caminho/para/harness-cycle-evolver.sh devtoharness-cycle-evolver.sh chama claude -p "/harness-evolve devto". A skill por dentro faz 3 coisas: resume os logs das últimas 4 semanas, preenche o template de proposta com um bloco diff, manda Telegram com o EVO-NNNN.
O contador sequencial está num arquivo único core/data/evolution-counter.txt, com flock para exclusão mútua. Sem banco, sem fila. Quando você aprova:
core/harness-evolve.sh approve EVO-0003Esse comando extrai o bloco diff do arquivo de proposta, roda git apply --check, aplica com git apply --index, faz commit, atualiza o frontmatter para status: applied e dispara Telegram. Tudo em shell. Zero LLM no caminho de aplicar.
Eu rodo sábado 09
porque a segunda-feira do Strategist já passou tempo suficiente para os logs estarem frescos, e o fim de semana é quando eu tenho 5 minutos para decidir aprovar ou rejeitar. Proposta chegando segunda 08 é proposta que vai me forçar decisão no início da semana de trabalho. Sábado 09 chega com café na mão.EVO-0003 — o que ele desenterrou
A terceira proposta de verdade do Evolver, EVO-0003, foi a que descrevi no começo. O arquivo está no disco e estou relendo enquanto escrevo isso.
A seção de observação citava os dois logs do meu Strategist, o “3 semanas seguidas em observação, decisão na próxima semana” e o “dados insuficientes, observar na próxima semana”. Depois calculou a engagement rate a partir do article-performance.jsonl e mostrou que o limite tinha sido rompido havia pelo menos 4 semanas. Depois argumentou que a regra original era ruim por 3 motivos:
- A fórmula não estava explícita. “Taxa de Reaction” era por artigo ou agregada? O Strategist conseguia calcular qualquer uma das duas, e essa ambiguidade dava espaço para postergar
- A condição “4 semanas seguidas” ficava ambígua quando os dados semanais eram fininhos
- A ação no disparo — “propor revisão de título e ângulo” — era abstrata o suficiente para o Strategist cumprir em uma frase e seguir em frente
A proposta substituiu a regra por isso:
Engagement rate = (soma de reactions + comments dos últimos 4 semanas de artigos) / soma de views. O Strategist precisa calcular toda semana e registrar no log. Se ficar abaixo de 1.5% por 4 semanas seguidas, na semana seguinte 4 dos 5 artigos têm que estar no formato “número + primeira pessoa + narrativa de fracasso”. Títulos abstratos estão proibidos.
Patch de 20 linhas. Aprovei terça-feira 14
via/harness-evolve approve EVO-0003. O shell rodou git apply --index contra strategy.md, criou o commit, atualizou o frontmatter para status: applied e mandou Telegram. Na segunda seguinte o Strategist rodou com a regra nova e calculou engagement rate de 1.35% no log sem ninguém pedir. A frase “dados insuficientes” sumiu.
A parte que quero ser honesto: o Strategist não estava agindo de má fé. Não estava nem quebrado. Era um agente competente seguindo uma regra estruturada para permitir adiamento. Isso é uma falha da regra. A tarefa do Evolver é pegar falhas de regra, porque mais nada no arnês foi montado para isso.
Limites para não deixar Evolver virar bicho solto
No segundo que você fala “agente que reescreve o arnês”, alguém na sua cabeça precisa levantar a mão e perguntar “o que impede ele de se reescrever virando otimizador de clipe?”. Várias coisas, todas de propósito.
O Evolver não pode tocar em algumas categorias de decisão. Adicionar ou remover domínio. Trocar idioma. Mudar o critério de qualidade do texto. Qualquer coisa que envolva licença, autoria ou segurança. O .env, o diretório de credenciais, os gatilhos de publicação. Se algumas dessas estivessem no escopo dele, eu não deixaria rodar sozinho de sábado de manhã.
Dentro do que ele pode tocar, três limites numéricos seguram a coisa.
- diff de até 20 linhas por proposta. Maior que isso, divide ou vira escalation
- 2 propostas por semana por domínio. A 3ª espera o próximo sábado
- 3 rejeições seguidas no mesmo tema dispara mute automático. O Evolver para de re-propor a mesma ideia depois de eu falar não três vezes
O terceiro é o que eu acho que a literatura geral sobre “self-improving agent” subestima. O sinal interessante num log de reject não é a proposta, é o motivo. “MCP ainda é o gênero principal de venda de livro, não dá para cortar” é um tipo de contexto de negócio que nunca foi escrito no strategy.md. Depois de 3 semanas rejeitando propostas de cortar MCP com esse mesmo motivo, o Evolver para de propor cortar MCP. Contexto implícito de fundador vira comportamento explícito do arnês só pela acumulação de motivos-de-rejeição.
Sequela direta do post de 3 camadas
A separação Observer/Strategist/Marketer eu já escrevi em outro artigo. Aquele era sobre “de 1 agente para 3 agentes, 20 minutos viraram 3”. Este aqui é sobre reescrever a regra que essas 3 camadas seguem.
A separação em 3 camadas era pela velocidade e previsibilidade. A 4ª camada é por prestação de contas. Mais do que “adicionei 1 camada acima das 3”, é “derrubei a hipótese implícita de que a regra é fixa”.
O que ainda não construí
O Evolver atual audita um domínio por vez. Nos meus 4 domínios (devto, qiita, zenn, kenimoto-dev) escrevo versões diferentes de strategy.md, e a maioria tem critérios de saída com estrutura parecida. Um Evolver cross-domain poderia notar que a mesma estrutura de regra está falhando em 2 domínios e propor um conserto unificado. Não fiz ainda. Está na lista.
A outra coisa na lista é a recursão óbvia. Quem audita o Evolver? Por enquanto a resposta é “eu, cada approve/reject é um sinal humano”. A resposta longa é “ainda não sei”. Se as propostas começarem a ter viés sistemático — sempre limites mais apertados, sempre cortar o mesmo gênero — esse viés é real e vai precisar de uma 5ª camada que vigia a 4ª. Ainda não vi. Pode ser que só veja perto do EVO-0050. Quero ver o viés antes de adicionar mais uma camada só para me sentir seguro.
Por enquanto: 3 agentes que seguem regras, 1 agente que audita as regras, 1 humano que aprova a auditoria. É o arnês mais enxuto que achei capaz de pegar a própria enrolação.
A definição de “arnês” em 5 frameworks (OpenAI, Anthropic, LangChain, Martin Fowler, academia), os AGENTS.md de 2 a 100 linhas, e o capítulo de Self-Evolving Agents que o Evolver vive — tudo está em Harness Engineering: De Usar IA a Controlar IA.
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev · TabNews
Este artigo foi útil?