AI Finds Your Page Three Ways. I Published the Same Fact in All Three and Timed Which Reached AI First.
For about a year I treated “getting cited by AI” as one problem with one knob. Write good structured content, add some JSON-LD, wait. When a page didn’t show up in ChatGPT, I assumed I’d written it badly. I’d go back and rephrase headings like a man reorganizing his sock drawer to fix the plumbing.
The mistake wasn’t the writing. It was thinking there was one door.
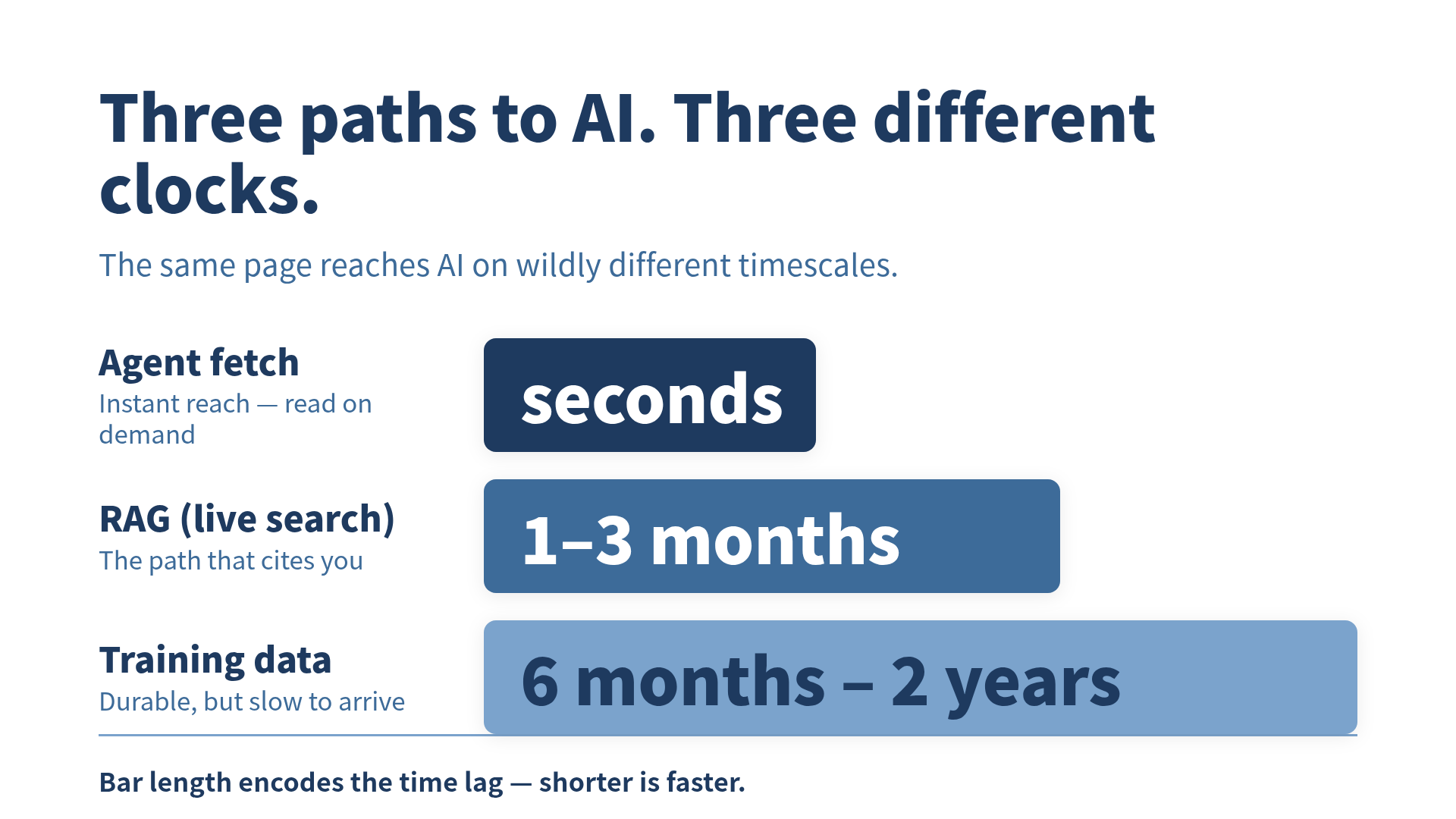
There are three. AI reaches your content through training data, through RAG (the live web search a model runs mid-answer), and through an agent fetching a page in real time. They are three separate pipelines wearing one label, and the single most underrated fact about them is that they run on completely different clocks. One reaches AI in seconds. One takes one to three months. One takes one to two years.
I got tired of guessing which was which, so I ran a small, dumb experiment: I published the same factual claim through all three paths and timed how long each took to surface in an AI answer.
The three doors, briefly
Before the stopwatch, the map. (If you want the full version with the optimization playbook per path, I keep it at llmoframework.com. This post is the field-notes version.)
Path 1 — Training data. The model’s “memory.” Whatever was baked into the weights during pre-training. When you ask ChatGPT how useEffect works and it answers without citing anything, that’s the training-data path. No sources, because it’s recalling, not retrieving.
Path 2 — RAG. The live search a model fires off mid-answer. ChatGPT’s web browsing, Perplexity, Google’s AI Overviews: all RAG. This is the path that cites you. If you’ve ever seen your URL show up as a little footnote in an AI answer, RAG put it there.
Path 3 — Agent fetch. An agent (or a browser-side assistant) pulling a specific page in real time, often outside the search index entirely. My own agent reads the web through Brave’s API; Claude in a browser tab can read the DOM of a page you have open. No “search engine” in the loop at all.
Here’s the part that reorganized my whole mental model.
The experiment
I picked one fact — a specific, checkable, slightly niche technical claim from my own work (a measured latency number from a voice-AI build, the kind of thing nobody else had published in that exact form). Then I pushed it out three ways on the same day:
- Put it in a structured blog post on my own site, with a question-style heading and the number right under it (the RAG play).
- Made sure the page was reachable by AI crawlers and well-formed enough for an agent to fetch cleanly (the agent play).
- Did nothing special for training data — because, as you’ll see, there’s nothing you can do that pays off this quarter.
Then I waited, and I kept asking the same question across ChatGPT, Perplexity, and my own agent, logging the first time my number came back.
Path 3 (agent fetch): same day
My agent had the number within hours, because “having it” just means the page exists and is fetchable. There’s no index to wait on, no crawl cycle, no retraining. The agent goes and gets the page when the question comes up. If your content is clean, structured, and not blocked, this path is basically instant.
The catch: instant reach, narrow audience. Agent fetch only helps when that specific agent decides to look at your specific page. It’s a real channel — it’s just not a broadcast.
Path 2 (RAG): a few weeks
This one took longer than “instant” and far less than “training.” The fact started showing up in Perplexity answers a few weeks after publishing, once the page had been crawled and indexed by the search backends these systems lean on. This tracks with what the broader data now says: in 2026, freshness is a primary citation signal. Content under 30 days old is pulling an estimated 3.2x more AI citations than older pages, and roughly half of all AI-cited content is now less than 13 weeks old (Authority Tech). RAG systems actively prefer newer sources when accuracy decays over time (Stellar AEO Labs).
So RAG is the path with the best effort-to-payoff ratio: weeks, not years, and it’s the only one that reliably puts your name in the citation.
Path 1 (training data): didn’t happen, and won’t for a long time
Two and a half months in, no model answers my question from memory. And it shouldn’t. Training data has a cutoff. A model trained up to some date in 2025 has never seen a thing I publish today. Retraining isn’t frequent; the gap from one major model generation to the next has historically run a couple of years. Anything I post this morning lands in the weights, optimistically, six months from now. Realistically, one to two years.
That’s not a failure. That’s the clock. Training data is the slowest, most durable path — once you’re in the weights, you’re in the “memory” for the model’s whole lifespan. But you do not optimize for it on a quarterly content calendar. You optimize for it by becoming the kind of source the web keeps quoting for years.
Why this matters more than the usual LLMO checklist
Most LLMO advice is a flat list: add JSON-LD, write an llms.txt, use question headings, keep it fresh. All fine. But a flat list hides the thing that actually wrecks people’s expectations — the lag.
I’ve watched people publish a great page, check ChatGPT a week later, see nothing, and conclude AI search “doesn’t work for them.” What actually happened is they shipped a RAG-and-agent asset and then went looking for a training-data result. Wrong clock. It’s like planting a tree on Monday and being annoyed there’s no shade on Tuesday.
Once you separate the paths by time:
- Need results this quarter? You’re playing Path 2 and Path 3. Structure for retrieval, stay fresh, stay fetchable. This is where new content earns its keep.
- Building a brand AI “knows” by default? That’s Path 1, and it’s a one-to-two-year investment in being cited, shared, and referenced enough that the next training run can’t ignore you.
They’re complementary and run on one engine. The same structured, original, genuinely useful page feeds all three; it just arrives at three different times. The efficient move is to optimize for RAG first, because that work spills over: a page clean enough for retrieval is clean enough for an agent to fetch, and original enough to get cited is original enough to eventually get learned.
The honest takeaway
The reason “I wrote a good post and AI ignored it” feels so personal is that we’re measuring a tree on a vegetable’s schedule. AI doesn’t find your page one way. It finds it three ways, on three clocks, and most of the frustration in this space is just someone staring at the slow door waiting for the fast door’s result.
Push your fact through all three. Then check the right clock.
If you want the full framework — the per-path optimization playbook, the crawler config, and how this connects to citation half-life — that’s the whole point of LLMO: AI Search Optimization.
Sources:
Was this article helpful?