AI Reads Your Chunks, Not Your Page: I Promoted 9 Sections from H3 to H2 and Watched Which Ones Got Quoted
I spent a week last month doing something that, written down, sounds like a cry for help: I went through my own blog and changed nine ### into nine ##. No new sentences. No new facts. I just promoted nine sections from H3 to H2, pushed the change, and then watched five AI engines for three weeks to see which of those sections started getting quoted. The thing I was testing was almost too dumb to admit out loud. It turned out to be the most useful afternoon of formatting I’ve done all year.
Here’s the idea I was chasing. When I ask an AI search engine a question and it cites my site, it almost never quotes the whole page. It lifts a piece: one paragraph, one table row, one code block, one section under one heading. And if AI quotes pieces, then the question that actually matters is not “how good is my page,” it’s “where does my page get cut into pieces, and is the good part its own piece or buried inside a bigger one.” Headings, it turns out, are the scissors.
Why the page stopped being the unit
The page stopped being the unit the moment retrieval started happening at the chunk level. Brave’s LLM Context API, which shipped in early 2026, is the clearest window into this I’ve found, because Brave documented its pipeline instead of leaving me to guess. It runs a normal web search to find pages, then does “deep content extraction” that breaks each page into smart chunks, then ranks those chunks, and then ships the top ones to the model. The granularity it names is not the page. It’s the paragraph, the table row, and the code block.
Sit with that for a second. The ranking step that decides whether your content reaches the model operates on fragments, not URLs. Your beautiful, internally-linked 3,000-word guide does not compete as a guide. Its paragraphs compete as paragraphs, against paragraphs from other sites, most of which the model will never even know shared a page with yours. You are not entering a horse in a race. You are entering each of the horse’s legs separately and hoping at least one of them finishes.
So the practical question becomes: what decides where one chunk ends and the next begins? Some of it is the model’s own segmentation, which I can’t touch. But a large, free, embarrassingly controllable part of it is the heading structure, because headings are the most obvious topic boundary in any document. A new heading is a new “this is a different thing now” signal, and chunkers love that signal because it’s cheap and reliable.
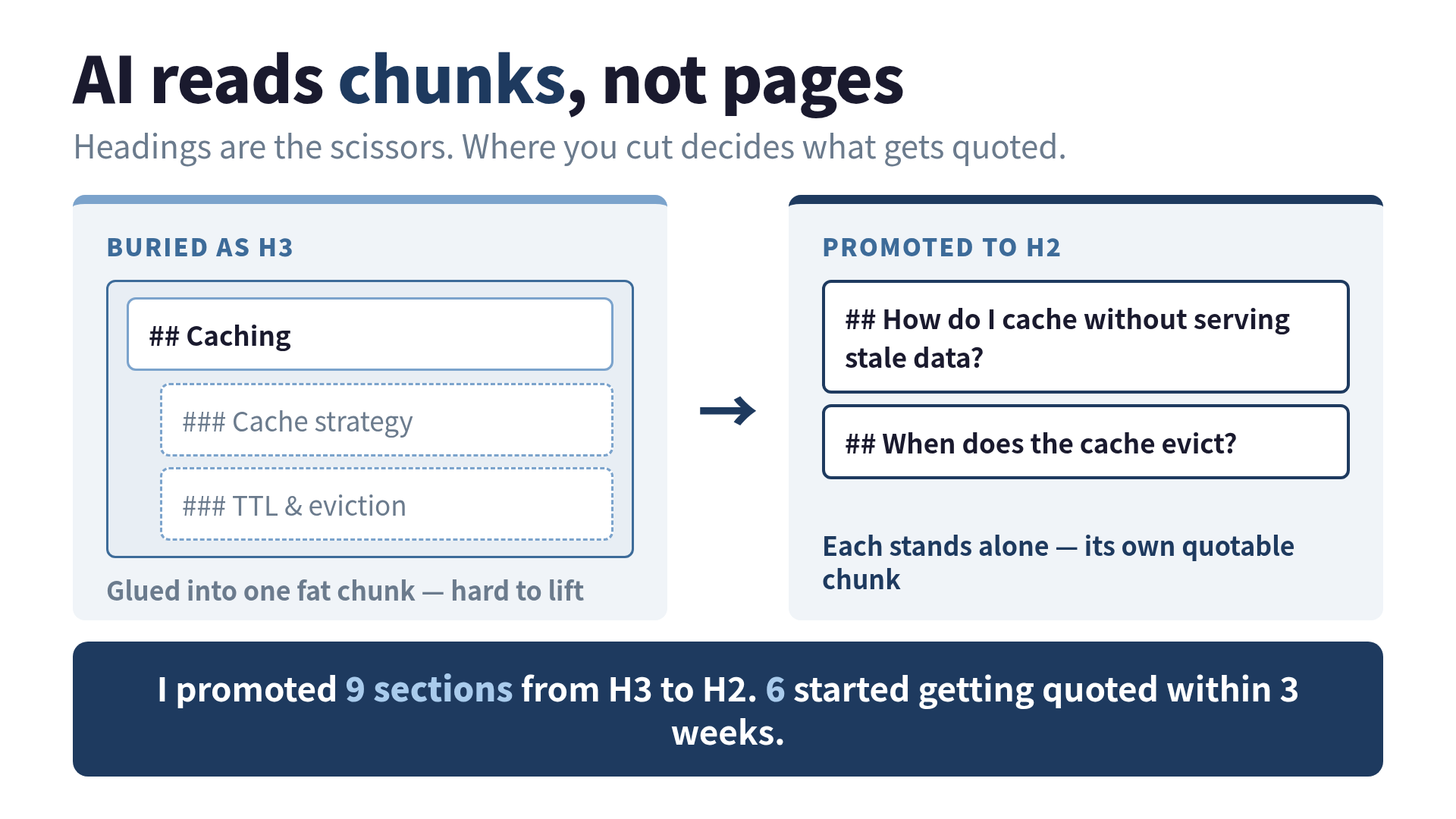
What promoting H3 to H2 actually changed
Promoting a section from H3 to H2 changes its status from “detail inside something else” to “thing in its own right.” That is the entire move, and it matters because of how nesting reads to a machine. An H3 sitting under an H2 is, structurally, a sub-point. The chunker is more likely to glue it to its parent or to the sibling H3s around it, producing one fat chunk that says “here are six considerations” instead of six lean chunks that each say one quotable thing. Promote that H3 to H2 and you’ve told every parser in the pipeline that this section stands alone. It becomes its own candidate. It gets its own shot at the ranking step.
This lines up with what the citation research keeps reporting. One 2026 analysis of content structure for AI retrieval found that LLM citation rates rise about 2.2x with a clear hierarchical heading structure, simply because clean hierarchy makes content easier to parse and extract. The same body of work keeps finding that question-shaped headings get pulled as candidate answers far more often, because the models were trained on Q&A-shaped text and a heading that matches how someone phrases a query is a flare going up over the answer.
I should be honest about what I did and didn’t change, because “I rewrote for AI” has become a sentence that means nothing. I did not touch JSON-LD. I did not change publish dates or add freshness signals. I did not rewrite the prose under the headings. On the nine sections I touched, I changed exactly two things: the heading level, and the heading text, which I rewrote from a label into a question wherever a real person might actually type that question. “Caching strategy” became “How do I cache API responses without serving stale data.” Same paragraph underneath. Different sign over the door.
The 9 sections, and the 6 that moved
Of the nine sections I promoted, six started showing up as citations within three weeks. Three didn’t move at all. I ran the same 20 prompts across ChatGPT, Perplexity, Gemini, Claude, and Brave every few days and logged which of my sections got lifted. I want to flag the obvious caveat before anyone with a statistics degree does it for me: n=9 on one small blog over three weeks is a field note, not a finding. AI citations also drift on their own for reasons I can’t see, so some of this is noise in a lab coat. Treat it as one engineer’s measurement rather than a law.
The six that moved had a trait in common, and it wasn’t the H2 by itself. Each one answered a real question in its first sentence and then stayed on that single question for the rest of the section. The promotion gave them a clean boundary; the self-contained content gave the chunker something worth keeping inside that boundary. The heading opened the door and the first sentence was standing right there when the engine knocked.
The three that didn’t move taught me more, the way the five that failed in my answer-first experiment did. Two of them were now H2 sections about topics nobody queries: “On the philosophy of caching” is not a question anyone types, so promoting it just gave a clean boundary to a chunk no one was searching for. The third was an H2 whose section wandered across three subtopics, so even with a standalone boundary, the chunk it produced was a mush that answered none of the three questions cleanly. The lesson was blunt: a good boundary around bad content just produces a well-labeled chunk that still loses.
Heading density is the part nobody talks about
Once I started thinking in chunks, I noticed the thing underneath the H2-vs-H3 question, which is heading density: how many words you run between headings. This is the dial that nobody mentions because it’s boring, and it might matter more than the level.
If you write 800 words under one heading, you’ve handed the chunker one enormous chunk to either keep whole, which blows the token budget, or split arbitrarily down the middle of your argument, which is worse. If you put a heading every 150 to 250 words, you’ve pre-cut the page along the seams you chose instead of the seams a segmentation model guesses at. You become the one holding the scissors. I now aim for a heading roughly every 200 words on anything I want quoted, not because 200 is magic but because it keeps each chunk down to a single idea that can stand alone, which is the whole game.
There’s a failure mode at the other end, and I walked into it. After this experiment I got greedy and over-chunked a page into headings every 40 words, which fragmented one coherent explanation into seven gasping little stubs, none of which said anything complete. The engines quoted none of them. A chunk still has to be a whole thought. Headings decide where the cuts land; they don’t excuse you from having something worth cutting.
What I actually do now
The routine I landed on is short enough to fit in my head. Before publishing anything I want AI to quote, I list the real questions a person would type to land on it, I make sure each of those questions is an H2 and not an H3 buried two levels down, I answer the question in the first sentence under each heading, and I keep each section to one idea and a couple hundred words. That’s it. No schema gymnastics required to get started, though structured data and the rest of the implementation layer still earn their keep once the structure is right. If you want the structural side written up properly, with the heading and chunk-boundary patterns laid out as an implementation guide, the LLMO framework reference collects them in one place, and it’s where I send people who want the spec rather than the war story.
The reframe that stuck with me is this: stop writing pages for an AI to read and start writing chunks for an AI to lift. Your reader still gets a page, scrolling top to bottom like a civilized person. But the machine deciding whether to cite you is reading a pile of fragments, and your headings are the only part of the cutting you get a vote in. I spent years optimizing for machines that can’t laugh. The least those machines can do is quote me correctly, and it turns out the way to make them is to cut the page up myself before they do it for me.
If you want the full field guide to being seen by AI search engines — from chunk-friendly structure to JSON-LD, llms.txt, and citation-rate KPIs — I wrote it all down in Why ChatGPT Ignores Your Website.
Was this article helpful?