I Ran Claude Code, Cursor, and Codex in Parallel for a Day. The Real Cost Was 412 Decisions.
I have three agents on my desk right now. Claude Code on the left monitor. Cursor with a background agent humming through tickets on the right. Codex CLI on a tmux pane below them, working a long-running data-migration script. Two weeks ago I told my partner I had finally found “the unfair advantage.” Three agents in parallel. About three engineers’ worth of throughput. The math was so clean I almost wrote a blog post the first day.
I never wrote that post. I wrote this one instead, because I taped the entire workday and counted the decisions.
The total was 412.
Four hundred and twelve y/n calls in eight hours: accept this diff, reject that diff, approve this tool call, kill that runaway, switch tabs, pick which agent’s answer to merge. That’s roughly one judgment every 70 seconds, every minute I was conscious at the desk. By 2
I approved a Cursor patch that broke a typed event I had hand-written that morning, and I didn’t notice until the next day’s PR review. The diff was 14 lines. I had looked at it for nine seconds.The dollar cost was the boring part. The decision cost was the lever.
The setup I tried to justify with throughput math
The three-agent setup is the natural shape once Anthropic and Cursor both shipped parallel sessions this spring. Anthropic rolled out the Agent View dashboard on May 11, 2026, the full desktop redesign with parallel sessions in April, and then Dynamic Workflows on June 12 so a single Claude Code session can spin up dozens of sub-agents across multiple repos. Cursor’s Background Agent went GA in 1.0 earlier this year — each background task gets its own worktree, its own model session, its own log stream. Codex CLI sits in the same shape.
So my desk looked like the docs told me it should:
- Claude Code: feature branch, voice-AI refactor, full main session plus two backgrounded sub-agents
- Cursor: background agent on
fix/og-emit, handling a queue of three lint tickets unattended - Codex CLI: a long-running schema migration, running with
--autoin a worktree
I had run the cost math the week before. Three agents in parallel, generous Sonnet usage all day, came out to roughly $9 of metered API plus the two flat subscriptions I already had. That’s not a problem. That’s a rounding error. I closed the spreadsheet and felt smug.
The cost I had not modeled was the one I was about to pay with my afternoon.
I measured one day. Here is exactly what I did.
I wanted a number, not a vibe. So I instrumented the desk.
# tmux: log every keystroke timestamped to a file
script -f -q ~/logs/2026-06-23-desk.log
# claude-code: print mode so every accept/reject is structured
claude-code --print --verbose > ~/logs/2026-06-23-claude.jsonl
# cursor: read the .cursor/logs/ stream after the fact
# codex: ~/.codex/history.jsonl already structured by defaultThen I worked normally from 09
to 17, with one 45-minute lunch. Afterwards I wrote a 30-line Python script that counted, per source:- accept / apply / yes / [enter] events on a diff
- reject / discard / no / esc events on a diff
- explicit “switch agent” or “pick this one” between competing outputs
- approve-tool-call prompts (Bash, Write, MCP)
I didn’t count typed characters in the prompts themselves. I didn’t count reading. Just the binary judgment moments.
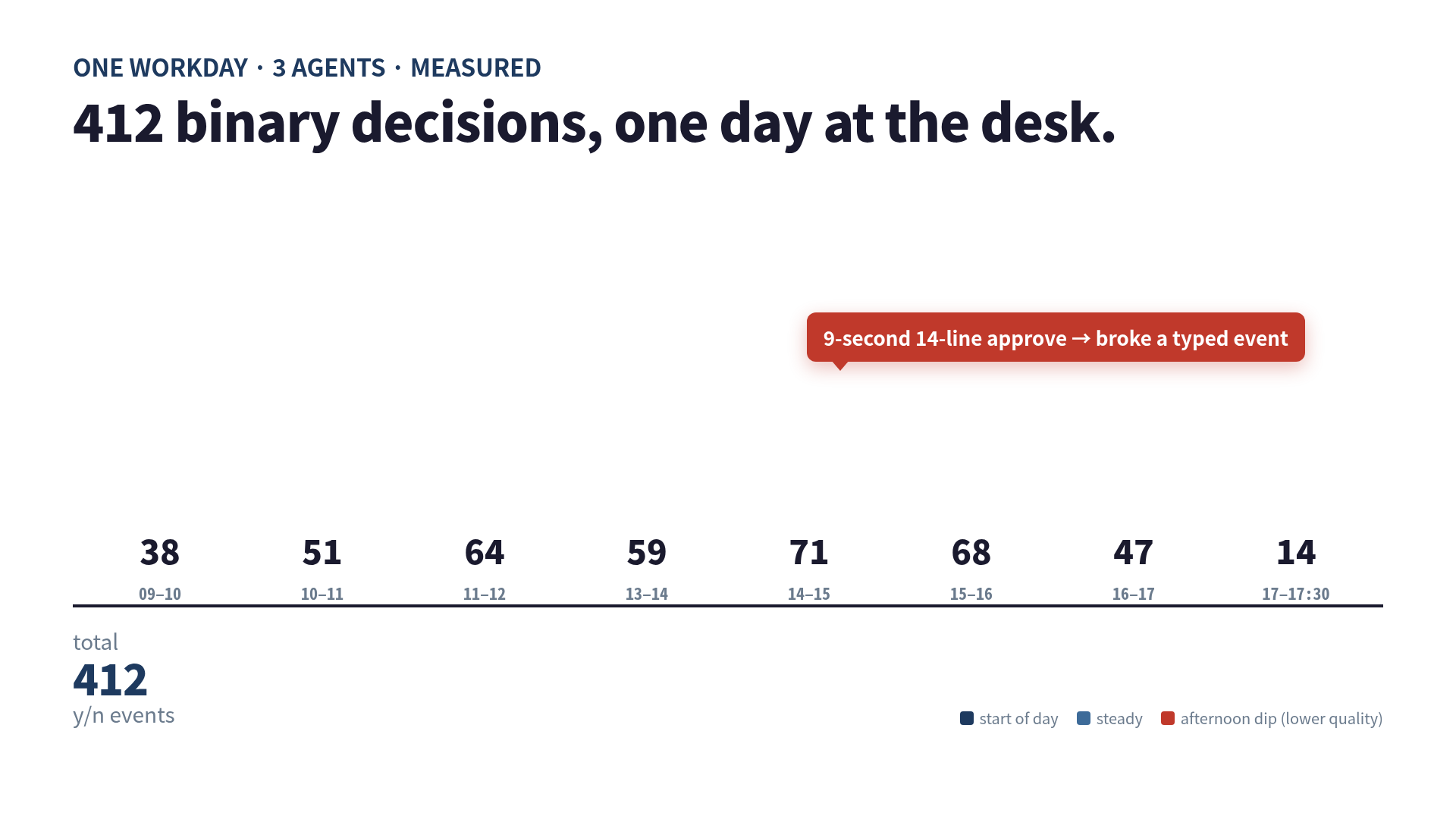
The total came out at 412. The bigger surprise was the shape of the day, not the size of the total:
| Hour | Decisions | Note |
|---|---|---|
| 09–10 | 38 | Setup + small early diffs, careful |
| 10–11 | 51 | Cursor’s background agent finished its first ticket |
| 11–12 | 64 | Three streams active, peak throughput |
| 13–14 | 59 | Post-lunch, still sharp |
| 14–15 | 71 | Felt productive — was actually shallow |
| 15–16 | 68 | The bad merge happened here |
| 16–17 | 47 | Slowed myself down deliberately |
| 17–17 | 14 | Done |
The number I thought I would see was something like 150. I had estimated 150 before I taped the day. The real number was nearly three times that, and almost all of the extra came from the two background agents quietly serving me decisions in chunks I had not budgeted for.
Why 400 decisions a day is a real problem, not a vibe
You can dismiss “I felt tired” as folklore. You cannot dismiss the studies.
Roy Baumeister’s group ran the classic decision-cost experiment back in Vohs et al. 2008. Two groups of students were asked about the same products. Group A had to choose between them. Group B only had to rate them. Afterwards both groups did unrelated cognitive tasks. The choosers did worse. Same information load, just the act of deciding changed the rest of the day.
The ego-depletion framing from that era has gotten beaten up in replication work (and the Strength Model review is honest about that). I don’t need the strong “fuel runs out” claim. I just need the weak version: a long run of decisions degrades the next decision. That weak version replicates everywhere you look.
Including in court. Danziger et al. 2011 in PNAS studied 1,000+ parole hearings by eight Israeli judges across 50 days. Approval right after a meal break: ~65%. Approval just before the next break: near 0%. Same judges, same case mix, time-of-day made the call. There are legitimate critiques of the case ordering, fine. The exact slope is contested. The shape of the curve isn’t.
A judge is making a bigger decision than I am. But the structural pattern, same decider, long unbroken sequence of binary calls, no recovery in between, is the same pattern I just measured on my own desk. My afternoon dip wasn’t a personality flaw. It was a parole rate.
Then there is the AI-specific layer on top. Towards Decoding Developer Cognition in the Age of AI Assistants makes the point cleanly: reading an AI suggestion is not the same cognitive shape as reading code you wrote. You have to back-solve the model’s logic into your own mental model before you can decide whether to accept it. The CHI 2026 paper When Help Hurts: Verification Load and Fatigue with AI Coding Assistants measured this directly on 60 developers — subjective workload went down with AI assistance, completion time went down, but a behavioral “verification load” metric went up, and that load tracked stress and quality drift across repeated use. The 18-point subjective relief was effectively borrowed from the next afternoon.
Each accept I do on three agents in parallel is not a 70-second event. It is a 70-second event surrounded by a verification cycle the studies say accumulates.
The harness moves I actually changed after the measurement
I did not stop running three agents. The throughput is real. The fix is not “use fewer agents,” it is “make most of the 412 calls disappear before they reach me.”
These are the four moves I made the week after the tape. They cut the day from 412 to 168 without changing the number of agents on my desk.
Pre-approve the diffs that don’t need a human eye. Most of those 412 were not interesting choices. They were tiny lint fixes, import sorts, prettier re-runs, single-line type imports. I added an allow-patterns.json that auto-accepts those classes of diffs at the harness level. ~120 events vanished. Quality did not move. I write more about this layering in Harness Engineering — the book version of “judgment is human, execution is the agent.”
Pre-reject the patterns I never want. A short denylist: no eval, no shell-out to curl | sh, no edits to my secrets dir, no MCP servers I haven’t whitelisted. Anything matching gets auto-rejected with a one-line log. ~40 events vanished. None of them were ever going to survive review anyway.
Stop running redundant agents on the same task. I was asking Claude and Cursor to suggest fixes for the same lint queue out of laziness, then picking the better one. I was paying a “pick-the-winner” decision tax on every ticket. I now route each class of work to one agent. ~50 events vanished, mostly the worst kind: the ones where I had to compare two plausible-looking outputs and decide which one’s logic was less wrong.
Front-load the high-stakes decisions to before lunch. Once I admitted the afternoon dip is real, the schedule became obvious. PR review, architecture calls, anything where being wrong costs me a week: those go in the 9am to noon block. The afternoon is for the boring two-thirds that the harness now auto-handles. The bad merge from 2
last week would have gotten caught by 10 me. So move 10 me to where the danger is.Total: roughly 412 → 168 on a comparable day a week later. Same three agents. Same dollar cost. About 60% fewer judgment events, almost all of the savings on the boring end of the distribution.
The number that actually mattered
When I started this measurement I thought I was going to write a post about the dollar bill. I had the spreadsheet open. I had cost-per-agent broken out by metered API vs. subscription. I had a chart.
The chart wasn’t the point. The chart was rounding error.
The point is that parallel agents bill you in two currencies. The dollar bill is the small one. The decision bill is the one you are paying with the second half of your workday, and it does not show up on any invoice. Until you tape a day and count, you will believe the dollar number is the whole story, the same way I did.
If you want one number to take away from this: count your own decision count, once. Don’t trust mine. Pick a normal day, run claude-code --print --verbose and script -f against your terminal, and at the end count the binary judgment events. Whatever number you get, you will pay that number tomorrow too. Then ask: which 60% of those could a harness have absorbed before they ever reached me?
That’s the question my afternoon should have been asking me at 2
, instead of waving through a 14-line patch in nine seconds.Want the full version of this argument? I work through the three-layer harness model — constraints, observability, automation — and the per-tool patterns that absorb decisions before they hit your screen in Harness Engineering. It’s the field guide for engineers who want to run multiple agents seriously without paying the verification tax with their afternoons.
Related on this blog:
Was this article helpful?