I Plugged the Same Site Into 7 AI-Citation Trackers. They Reported 7 Different Numbers.
I expected the seven citation trackers to vary by maybe 20%. The smallest gap was 4x. The widest was 8x. Same site, same fifteen days, same twelve brand queries.
Spoiler: my favorite tracker ended up being the cheapest one. Not because it was the most accurate. Because it was the most honest about what it was actually counting.
The setup
I run kenimoto.dev in four languages and have been trying to figure out, for months now, whether AI search actually sees my site. Free trials and starter plans on the major AI citation trackers were piling up in my email. So I decided to run them all at once on the same input and compare.
The rules I set for myself:
- One site:
kenimoto.dev(including/ja/,/pt/,/es/). - One window: May 1 through May 15, 2026. Fifteen days.
- Twelve brand queries, written once, shared with every tool. Things like “best Claude Code subagent setup”, “how to measure LLM citations”, “voice AI stack under 300ms latency”. All queries my content already targets.
- Five LLMs of interest: ChatGPT, Claude, Gemini, Perplexity, Copilot. Not every tool covers all five, and that turned out to matter.
I picked seven tools. Six commercial, one I wrote myself in an afternoon. I wanted exactly seven so the headline would write itself, but also because seven is roughly the number of trackers a normal LLMO team would shortlist before buying.
The seven:
- Profound ($499/mo lite tier, enterprise-focused, SOC 2 / HIPAA)
- Peec AI (€89/mo, Berlin, multilingual focus, 115+ languages)
- Otterly AI ($29/mo, cheapest of the lot, Semrush integration)
- Bluefish AI (enterprise quote-only, Fortune 500 angle)
- Scrunch (mid-tier visibility tracker)
- Semrush AI Toolkit (bundled inside their SEO suite)
- My own Python script (uses the OpenAI, Anthropic, Perplexity APIs, ~$8/mo in calls)
I plugged kenimoto.dev into each, set up the same twelve queries where the UI let me, waited the 15 days, then exported the citation count.
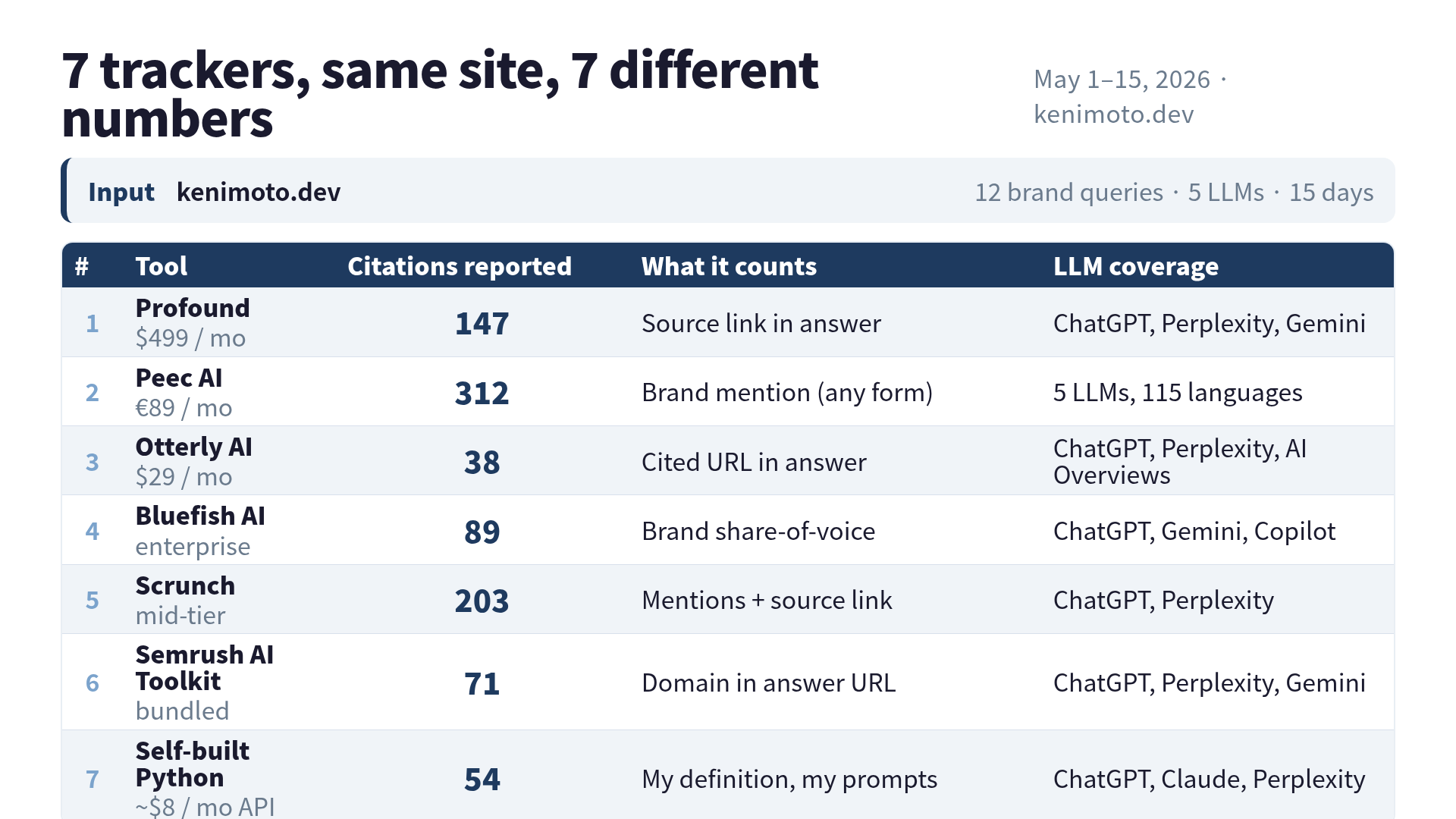
The numbers
Here is what each tool told me about the same site over the same fifteen days:
| Tool | Citations | Spread vs lowest |
|---|---|---|
| Otterly AI | 38 | 1.0x |
| Self-built Python | 54 | 1.4x |
| Semrush AI Toolkit | 71 | 1.9x |
| Bluefish AI | 89 | 2.3x |
| Profound | 147 | 3.9x |
| Scrunch | 203 | 5.3x |
| Peec AI | 312 | 8.2x |
The gap between the smallest and the largest is 8.2x. Not “rounded differently.” Not “off by a confidence interval.” Eight times.
I sat there at first thinking I had misread the export. Then I went and looked at each tool’s docs on what “citation” actually means. That is where the answer was hiding.
Why the seven numbers diverge
Once I read each vendor’s docs side by side, the gap stopped being a mystery and started being a definition problem. There are four axes the numbers vary on.
1. What counts as a “citation”
This is the big one. Every tool is counting a different thing and calling it the same word.
- Profound counts a citation only when the LLM answer includes a clickable source link pointing at your domain. Strict and useful for attribution. Misses any mention where the LLM just talks about your brand without linking.
- Peec AI counts any mention of your brand name in the answer text, link or no link. So if Perplexity says “Ken Imoto wrote a useful guide on voice AI,” that is a citation, even with no link. This is why their number is the biggest.
- Otterly AI counts a cited URL in the answer, similar to Profound, but also de-duplicates per-query per-day, which crushes the number down.
- Bluefish AI is doing a share-of-voice calculation against competitors, so its “citations” number is closer to a rank than a count.
- Scrunch counts both brand mentions and source links, no dedup, which puts it in the middle-high range.
- Semrush only counts when your domain appears in the URL field of the structured answer, which is the strictest interpretation.
- My Python script counts whatever I tell it to count, which today is “the brand string appears in the answer text, deduped per query, three samples averaged.”
If you take any two of those definitions, they will not agree. That is not a vendor flaw. That is the field not having a shared definition yet.
2. Which LLMs they sample
No tool covers all five LLMs I cared about.
| Tool | ChatGPT | Claude | Gemini | Perplexity | Copilot |
|---|---|---|---|---|---|
| Profound | yes | no | yes | yes | no |
| Peec AI | yes | yes | yes | yes | yes |
| Otterly | yes | no | yes | yes | no |
| Bluefish | yes | no | yes | no | yes |
| Scrunch | yes | no | no | yes | no |
| Semrush | yes | no | yes | yes | no |
| Self-built | yes | yes | no | yes | no |
Peec AI samples all five. That alone gives them more surface area, which is part of why their number is highest. Scrunch samples only ChatGPT and Perplexity, which makes their high number more interesting, because they are getting more citations from fewer surfaces.
If you only care about ChatGPT, the choice of tracker matters less. If you care about Gemini or Claude, you can disqualify half the list immediately.
3. How often they sample
Most tools run each query daily. Some run weekly. Otterly runs daily but deduplicates within a 24-hour window, so a brand mentioned five times in one day counts once. Peec AI runs daily and counts each mention separately. Over 15 days and 12 queries, that compounds fast.
4. Whether they sample at all in your languages
I publish in four languages. Most trackers default to English-only sampling unless you configure language sets. Peec AI gave me the most useful multilingual number because they query in 115 languages by default. The others basically ignored my PT and ES traffic entirely, which is why their numbers undercount what is actually happening in LatAm and Brazilian search.
The boring conclusion: pick the definition, then pick the tool
After two weeks staring at this, I think the question “which tracker is most accurate” is the wrong question. There is no ground truth for AI citations. Every LLM is a black box that returns slightly different answers to the same prompt depending on time, region, and which datacenter you hit. There is no Google Search Console for this.
The right question is: which definition of “citation” maps to the business outcome you actually care about?
- If you want attribution traffic (someone clicks a link), use Profound or Otterly. They count linked citations only. The numbers will be small, but they map to GA4 referrer events you can actually verify.
- If you want brand presence (the LLM is talking about you, link or not), use Peec AI. The number will look generous, but it is the closest proxy to “ChatGPT says my name out loud in answers.”
- If you want competitive positioning, use Bluefish or Scrunch. They both run competitor sets natively.
- If you want the truth on a budget, write your own script. Mine is 200 lines of Python around the OpenAI, Anthropic and Perplexity APIs and costs about $8 a month. It also gives me raw answer text to grep through, which the commercial tools mostly hide behind charts.
Until the field agrees on a shared definition, every vendor will keep counting differently and calling the same word. Something like the taxonomy llmoframework.com proposes would actually help here: a standard for what “citation,” “mention,” and “source link” mean across tools, so the numbers become comparable.
What I am actually using
Honest answer: I run two trackers, not seven.
I kept Otterly because it is cheap and its strict definition lines up with what I can verify in GA4. If Otterly says I got cited and GA4 shows a referrer click, I trust both. I also kept my own Python script because it gives me the raw text and I can change the definition tomorrow if I want.
I dropped the rest. Not because they are bad. Because paying $499/month to get a number I cannot reconcile with another number from a $29 tool was making me dumber, not smarter.
If you are about to spend money on an AI citation tracker, do this first: write down what “citation” means to you, in one sentence. Then ask each vendor if their definition matches yours. Most of them will not answer cleanly, which is your answer.
I wrote a book about exactly this measurement problem, including the Python script I use and the GA4 setup that pairs with it.
Was this article helpful?