Audité 30 archivos llms.txt en producción. 5 anti-patrones ya se están formando.
Subí mi tercer llms.txt este mes y me sentí injustamente productivo. Ese tipo de productividad donde cierras la computadora, te sirves un café y tienes cara de que ya resolviste solo el problema de búsqueda con IA.
Después abrí 30 archivos llms.txt en producción de las empresas que la gente cita cuando quiere convencer a alguien de que “mira, los equipos serios ya hacen esto”. Anthropic. Stripe. Vercel. Cloudflare. Hugging Face. Mintlify. Astro. Linear.
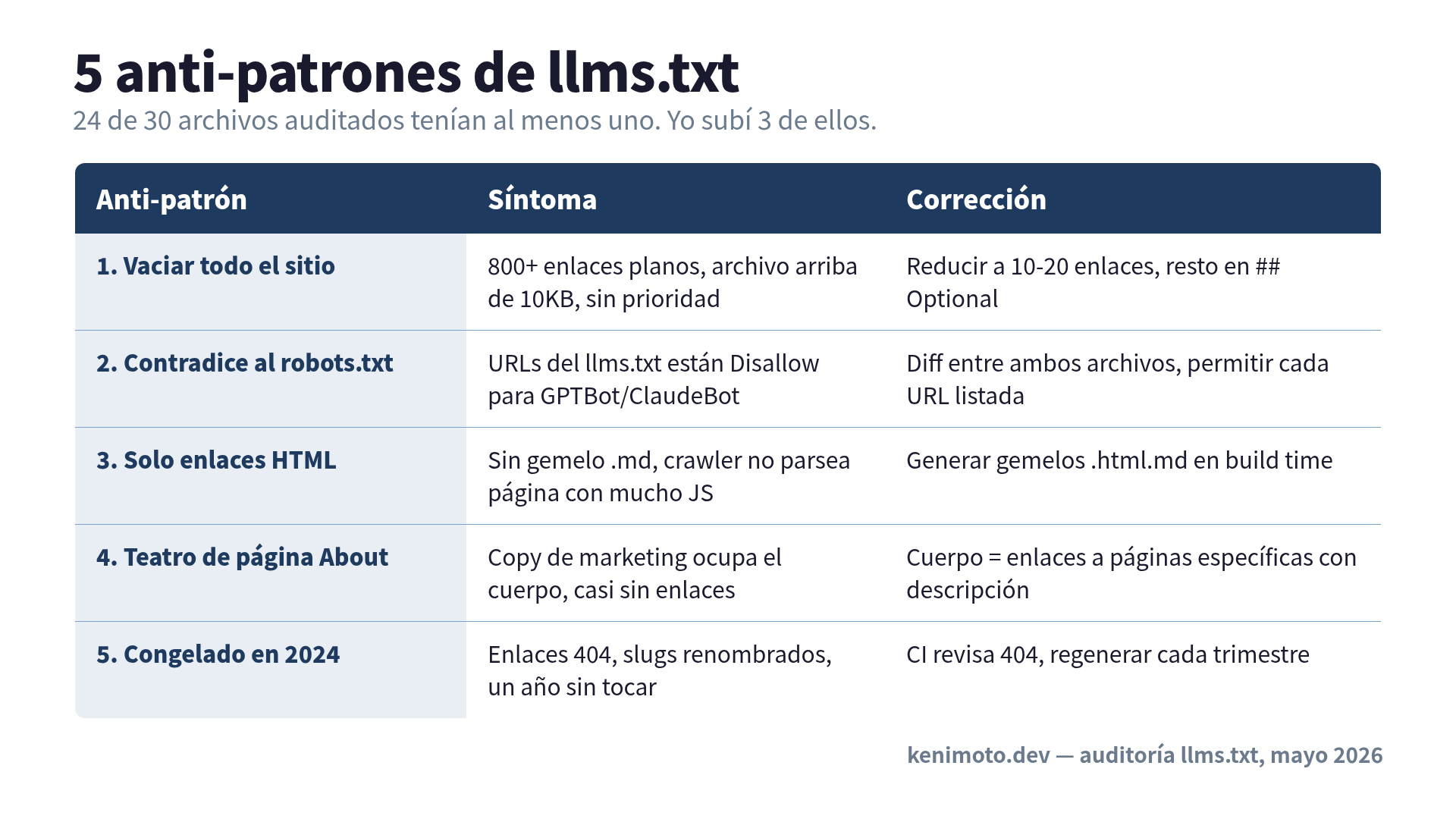
24 de los 30 tenían al menos uno de cinco problemas. Tres de esos problemas yo también los había cometido.
El café se enfrió.
Este artículo es una guía práctica. Si tú quieres auditar tu propio llms.txt antes de que un agente de IA lo descarte en silencio, acá tienes el procedimiento completo, los cinco patrones más comunes y un script bash mínimo para automatizar la revisión.
Cómo hice la auditoría
El montaje fue vergonzosamente simple. Tomé 30 dominios con llms.txt público que importan para personas que desarrollan en 2026: labs de IA, infra de nube, herramientas de desarrollo. Hice curl a cada uno. Leí cada archivo con la cabeza de un LLM tratando de usarlo. Anoté lo que estaba mal.
No es ciencia. Es lunes por la noche con la terminal abierta. Pero los patrones aparecieron tan rápido que paré en los 30. Los siguientes diez iban a ser más de lo mismo.
Como referencia: el estudio de SE Ranking con 300 mil dominios de marzo de 2026 encontró cerca de 10% de adopción. La guía de codersera de mayo de 2026 estima 844 mil sitios con crecimiento de 500% anual. La adopción está ganando la carrera. La calidad la está perdiendo.
Script de auditoría mínimo
Antes de los patrones, te dejo el script que usé. Quince líneas, sin dependencias raras. Pásale una lista de dominios y te dice los errores más obvios.
#!/bin/bash
# audit-llms-txt.sh — auditoría mínima de llms.txt
# Uso: ./audit-llms-txt.sh dominios.txt
while read DOMAIN; do
URL="https://${DOMAIN}/llms.txt"
CONTENT=$(curl -sL --max-time 10 "$URL")
SIZE=$(echo "$CONTENT" | wc -c)
LINKS=$(echo "$CONTENT" | grep -cE '^\s*-\s*\[')
MD_LINKS=$(echo "$CONTENT" | grep -cE '\.md\)')
if [ -z "$CONTENT" ]; then
echo "[FALTA] $DOMAIN"
continue
fi
echo "[$DOMAIN] tamaño=${SIZE}B enlaces=${LINKS} con_md=${MD_LINKS}"
[ "$SIZE" -gt 10240 ] && echo " AVISO: tamaño > 10KB (anti-patrón 1)"
[ "$LINKS" -gt 20 ] && echo " AVISO: más de 20 enlaces (anti-patrón 1)"
[ "$MD_LINKS" -eq 0 ] && echo " AVISO: ningún enlace .md (anti-patrón 3)"
done < "$1"Esto no cubre los cinco patrones, pero atrapa los dos más comunes en menos de un minuto sobre 30 dominios. Para los otros tres patrones necesitas leer el archivo con tu propia cabeza.
Los cinco anti-patrones
Anti-patrón 1: “Vaciar todo el sitio”
El más común, y el que yo más cometí. La persona autora trata llms.txt como un segundo sitemap. 800 enlaces. 1.200 enlaces. Un archivo que abrí tenía cada post de blog desde 2019, plano, sin prioridad, sin agrupar.
El punto entero de llms.txt es que el sitemap.xml ya hace eso. Cuando la spec dice “10KB recomendado” no está siendo amable con el tamaño del archivo. Está diciendo: si el LLM no puede leer el archivo entero dentro de una ventana de contexto con presupuesto sobrante para la pregunta real, no ayudaste, solo moviste el problema de lugar.
La corrección es brutal: elige 10 a 20 enlaces. No 50. No “secciones principales más algunos extras”. 10 a 20. Todo lo demás va a ## Optional o se queda en el sitemap.xml.
Si tu producto tiene mucha documentación, usa el patrón de Cloudflare: un llms.txt raíz delgado que apunta a un llms.txt por producto. Cada uno cabe en el presupuesto. El agente solo descarga lo que necesita. Nadie lee la enciclopedia entera para arreglar una llave de agua.
Anti-patrón 2: “Contradice al robots.txt”
Abre el robots.txt. Abre el llms.txt. Compara las rutas. Cerca de un tercio de los archivos que audité listan URLs en el llms.txt que están explícitamente Disallow-eadas en el robots.txt para los crawlers que más probablemente leerían el llms.txt.
El ejemplo más doloroso: un sitio de documentación que bloquea GPTBot y ClaudeBot de /docs/ en el robots.txt, y después lista 40 URLs de /docs/* en el llms.txt. El archivo dice “esto importa”. El robots.txt dice “no puedes pasar”. El crawler obedece al robots.txt. El llms.txt es decoración.
Esto suele pasar cuando los dos archivos los mantienen equipos distintos (o la misma persona en meses distintos). La corrección son cinco minutos con los dos archivos abiertos en pantalla: cada URL en el llms.txt necesita estar permitida en el robots.txt para cada crawler de IA que de verdad quieres que la lea.
Si genuinamente quieres bloquear crawlers de IA, está bien, pero entonces no escribas también para ellos un directorio cortés con tus páginas favoritas.
Anti-patrón 3: “Solo enlaces HTML, sin .md”
La propuesta original de Jeremy Howard incluye una convención inteligente: cualquier URL con .md agregado debería devolver una versión Markdown limpia de la página, sin nav, sin ads, sin bundle de JavaScript. El patrón .html.md.
Casi nadie lo hace. En mis 30 archivos, solo 6 servían algún acompañante .md. Los otros 24 le entregan al LLM un enlace a una página HTML que el crawler no puede parsear bien porque no ejecuta JavaScript.
Stripe lo hace bien: cada URL de docs tiene un gemelo .md y el llms.txt apunta a la versión .md. La sección de Reference Templates de llmoframework.com marca esto como lo de mayor palanca que la mayoría de los equipos está saltándose, porque es la diferencia entre “la IA encuentra la página” y “la IA puede leer lo que hay en ella”.
La corrección depende de tu stack. Para Astro y Next.js, generar versiones .md en build time son 30 líneas. Para CMS dinámicos, una edge function que devuelve la serialización markdown en el sufijo .md resuelve. De cualquier forma, es el anti-patrón con mayor diferencia entre esfuerzo y resultado.
Anti-patrón 4: “Teatro de página About”
Ocho de los 30 archivos usaban el cuerpo entero del archivo como pitch de marketing. Tres párrafos sobre la misión de la empresa. Una cita del fundador. La historia de la marca. Y dos enlaces. Contenido total: “somos líderes visionarios en el espacio AI-native”.
Los LLMs no compran tu vibra. Necesitan punteros a contenido. El H1 y la cita en blockquote son el lugar para “qué es este sitio”. Todo lo demás debería ser enlaces a páginas específicas con descripciones específicas. Si tu llms.txt parece una homepage, escribiste una homepage.
El estudio GEO de Princeton sobre las 9 formas de ser citado por IA golpea el mismo punto del lado del contenido: las afirmaciones vagas no son citadas, las afirmaciones específicas con fuentes sí. La misma lógica aplica al propio llms.txt.
Anti-patrón 5: “Congelado en 2024”
Cinco de los archivos que audité tenían señales visibles de haber sido subidos una vez y nunca más tocados. Enlaces a páginas con 404. Nombres de productos que ya no existen. Fechas que ponen la última actualización significativa en 2024, cuando llms.txt era una propuesta de seis meses de vida y “búsqueda por IA” todavía era algo que Perplexity tenía que explicarle a la gente.
sitemap.xml se auto-genera. robots.txt rara vez cambia. llms.txt vive en un punto medio raro: curado a mano como documentación, pero con el mismo riesgo de obsolescencia que un README que dice “usamos Yarn” cuando el equipo migró a pnpm hace un año.
La corrección es automatización, no disciplina. Agrega un check de CI que marca 404 en las URLs que tu llms.txt lista. Regenera la sección de “artículos destacados” desde tu analítica cada trimestre. Trata el archivo como artefacto de configuración, no como entregable de lanzamiento.
El análisis de Mintlify sobre ejemplos reales de llms.txt marcó este como el segundo patrón más común en su base de clientes. El primero fue el Anti-patrón 1. Esos son los dos para atacar esta semana.
Contexto LatAm
Hice curl a varios dominios latinoamericanos y de España también. mercadolibre.com no tiene llms.txt (snapshot de mayo 2026). rappi.com tampoco. despegar.com idem. globant.com idem. mercadopago.com idem.
Esto se puede leer de dos formas. “LatAm está atrasada” es la lectura desanimada. “La persona que suba un llms.txt decente ahora todavía agarra ventaja de early adopter en el mercado regional” es la lectura constructiva. Yo me quedo con la segunda. En español, mayo de 2026, este sigue siendo terreno casi virgen entre productos de software grandes.
Los tres que yo subí
Sección de la honestidad. De mis tres llms.txt:
- Uno tenía 47 enlaces. Anti-patrón 1.
- Uno apuntaba a URLs solo HTML porque yo no había configurado el gemelo
.mdtodavía. Anti-patrón 3. - Uno llevaba 4 meses sin actualizarse y listaba un post con un slug que yo había renombrado. Anti-patrón 5 más una cadena de 301 de postre.
No noté nada de esto hasta estar tres cuartos del camino leyendo archivos ajenos. La auditoría iba a ser sobre los demás. Terminó siendo sobre mí. Hay alguna lección ahí adentro, pero todavía estoy en la fase de la vergüenza y no la pude formular.
Qué cambió después de arreglar dos
Arreglé dos. El de 47 enlaces se redujo a 16 enlaces más una sección ## Optional. El que solo apuntaba a HTML ganó gemelos .md para las 16 URLs destacadas vía un build hook de Astro (unas 25 líneas, más fácil de lo que esperaba).
No te puedo decir “las citaciones de IA subieron X%” porque el archivo tiene una semana de vida y medir citación a este volumen es ruidoso. Lo que sí puedo decir es que ahora el archivo pasa un test de olfato que debería haber aplicado el día uno: “¿un modelo con ventana de contexto de 200K y diez pestañas abiertas preferiría este archivo al anterior?” Sí. Obviamente sí. El anterior era ilegible.
La posición honesta sobre llms.txt
Las personas escépticas tienen parte de razón. El estudio de SE Ranking de 300K dominios no encontró un lift mensurable en citación. Los LLMs principales no confirman públicamente que descargan el archivo. La spec no tiene sello del W3C.
Las personas escépticas también están parcialmente equivocadas. Los agentes de IDE (Cursor, Cline, Continue), parte de los motores de búsqueda con IA, y una lista creciente de integraciones MCP leen llms.txt hoy. La opcionalidad es real y el costo son quince minutos.
La pregunta real para 2026 no es “¿debo subir un llms.txt?”. Esa pregunta ya la resolvió el cálculo costo-beneficio. La pregunta es si el archivo que subes le da algo útil a un LLM o lo entrena para ignorar tu dominio. Los anti-patrones 1 al 5 son la diferencia entre esos dos desenlaces.
Checklist práctica para esta semana
Si todavía no subiste uno, empieza por las bases. Si ya subiste, pasa el tuyo por la auditoría de cinco preguntas:
- ¿Está bajo 10KB y bajo 20 enlaces (excluyendo
## Optional)? - ¿Todas las URLs listadas pasan en
robots.txtparaGPTBotyClaudeBot? - ¿Al menos las 5 URLs principales tienen un gemelo
.md? - ¿El cuerpo apunta a páginas específicas, no a copy genérico de marketing?
- ¿Fue actualizado en los últimos 90 días?
Si sacas 5 de 5, estás en el top 6 de los 30 sitios que miré, o sea en el top 20% de una muestra ya auto-seleccionada. Si sacas 3 o menos, tienes la misma tarde de lunes esperándote.
Estoy escribiendo mi cuarto llms.txt esta semana. Voy a pasarlo por esta lista antes de publicar. No me voy a sentir productivo después. Me voy a sentir como alguien que aprendió la misma lección tres auditorías seguidas.
Eso, me dicen, es como funciona la ingeniería.
Referencias
- Especificación llms.txt (Answer.AI): propuesta original de Jeremy Howard
- Estudio SE Ranking 300K dominios: adopción y efecto en citaciones
- Mintlify ejemplos reales: patrones y errores de empresas líderes
- llmoframework.com: framework LLMO completo con Reference Templates
ken imoto · WebRTC & Voice AI engineer · kenimoto.dev
¿Te resultó útil este artículo?