記事にArticle schemaを入れてもAIは私を著者と認識しなかった。著者エンティティを実装して引用の帰属が変わった話
自分のブログにArticle schemaを入れたとき、私はちょっと得意げでした。author フィールドに自分の名前を書いて、JSON-LDのバリデーターを通して、エラーゼロ。これでAIは「この記事はken imotoが書いた」と理解してくれる、と思っていました。
ところがしばらくして、AI検索の回答に自分の記事が引用されているのを見つけたとき、引用元として表示されていたのは記事のURLだけでした。書き手の名前はどこにもありません。AIにとって私の記事は「どこかのページ」であって、「ある人物が書いたもの」ではなかったのです。Article schema に名前を入れたのに、私は著者として認識されていませんでした。
冷静に考えれば当たり前でした。私は author に「井本」と文字列を書いただけです。世の中に井本さんは何人いるでしょうか。AIから見れば、それは住所のない表札のようなものでした。名前は書いてあるけれど、それが誰を指すのかを確かめる手段がない。この記事は、その表札に「これは実在のこの人物です」という配線を通すまでの話です。

なぜ Article schema だけでは帰属しないのか
Article schema は「このページは記事である」という型を宣言します。headline、datePublished、author といったフィールドが並びます。AIはこれを読んで「ここに記事がある」と理解します。ここまでは効きます。実際、構造化データが引用確率を押し上げることは私自身も別の検証で確認しました(別記事の AI Overviews 4条件の30日検証 では構造化データ密度だけが3.9倍の差を作りました)。
問題は author の中身です。多くのサイトはこう書きます。
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "WebRTCの輻輳制御を実装してみた",
"author": {
"@type": "Person",
"name": "井本 賢"
},
"datePublished": "2026-06-17"
}@type が Person になっているので、一見ちゃんとしているように見えます。私もこれで十分だと思っていました。しかしこの Person には url も sameAs もありません。AIにとってこの「井本 賢」は、その記事の中だけに存在する孤立した文字列です。隣のページに同じ名前があっても、それが同じ人だと確かめる根拠がない。同姓同名の別人かもしれない。AIは無責任な帰属を嫌うので、確信が持てない人物を引用元として名指しすることを避けます。
つまり Article schema は「記事の帰属」までしか面倒を見ません。「誰の主張か」という著者の帰属(attribution)は、別のレイヤーで明示してやる必要があります。そのレイヤーが Person エンティティと sameAs です。
Person + sameAs で同一性グラフを作る
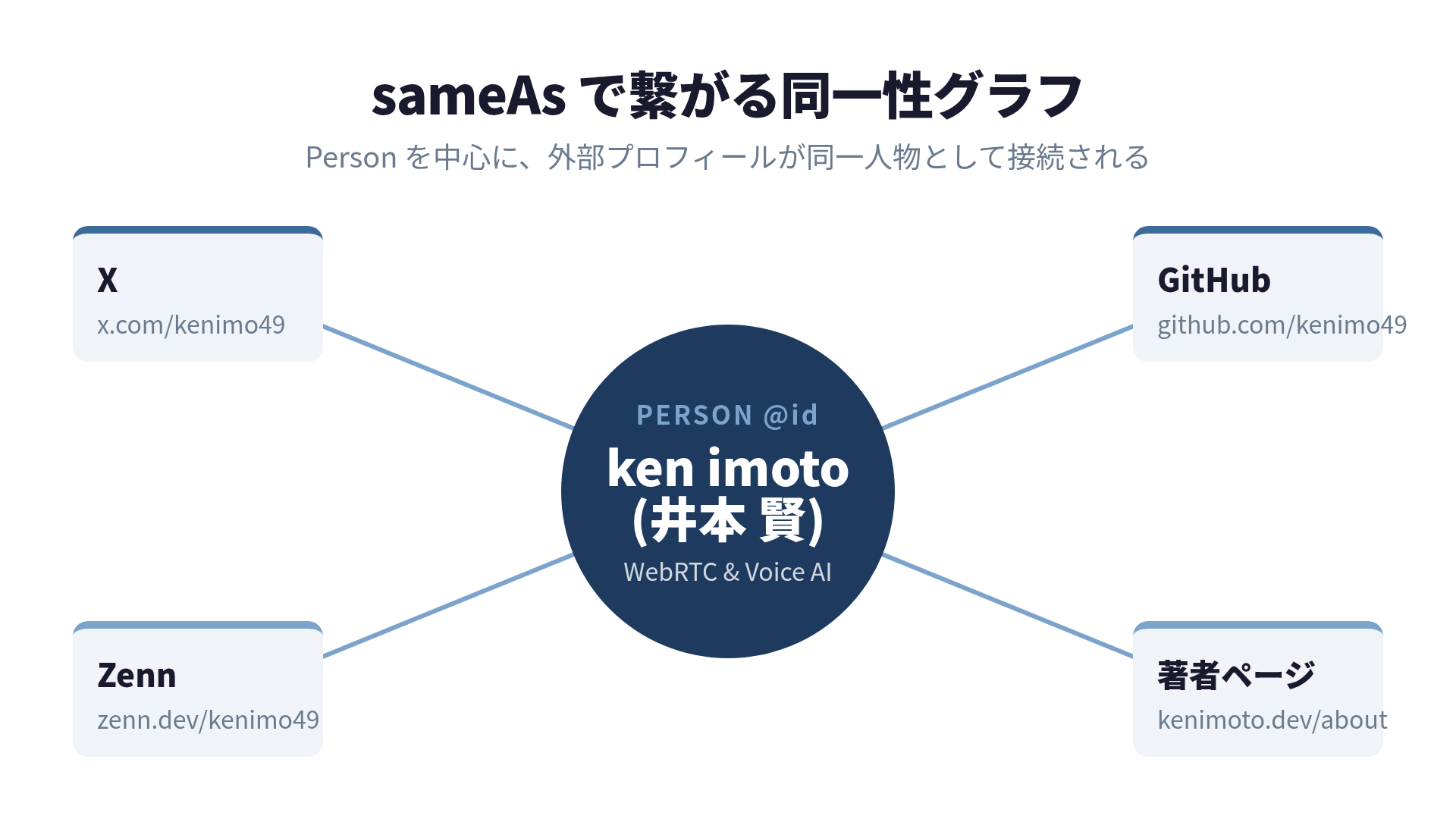
帰属を成立させる鍵は、sameAs という一見地味なプロパティです。これは「このPersonは、これらのURLにいる人物と同一です」という宣言です。X、GitHub、Zenn、自分の著者ページ。バラバラに散らばっている自分のプロフィールを、1つの実在人物に束ねます。
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://kenimoto.dev/#person-ken-imoto",
"name": "ken imoto",
"alternateName": "井本 賢",
"url": "https://kenimoto.dev/about",
"image": "https://kenimoto.dev/images/ken-imoto.jpg",
"jobTitle": "WebRTC & Voice AI Engineer",
"description": "WebRTCとVoice AIの実装を専門とするソフトウェアエンジニア。",
"sameAs": [
"https://x.com/kenimo49",
"https://github.com/kenimo49",
"https://zenn.dev/kenimo49",
"https://note.com/kenimo49"
]
}ここで何が起きているかを言葉にします。AIや検索エンジンは、この sameAs の配列を辿って、それぞれのプロフィールが本当に同じ人物に紐づくかを照合します。X のプロフィールから自分のサイトへリンクが張ってあり、サイトからXへ sameAs が張ってある。この双方向の整合が取れているほど、「この井本は実在のこの人物だ」という確信度が上がります。
実際、2026年の業界レポートを読み直すと、ここには定量的な裏付けが出てきています。複数の権威あるプロフィールにまたがるエンティティの一致は、引用の押し上げと相関するという分析があります。LinkedIn、X、その他の外部プロフィールが1つのエンティティ信号として束ねられると、引用率が大きく変わるという報告です(authoritytech.io の分析)。さらに、Perplexity の2026年2月のパブリッシャー向けガイドラインでは、構造化データが引用の重み付けをおよそ23%押し上げると言及されています(同レポート)。私が表札に配線を通したのは、まさにこの「確信度」を機械が計算できる形で渡す作業でした。
ちなみに sameAs を3つ4つ並べただけで一夜にして著者扱いされるわけではありません。同じ業界分析によれば、Person schema と検証可能な sameAs、そして特定トピックでの一定数の記事の蓄積がそろって、ようやく3〜6ヶ月で測定可能な変化が出始めるとされています。即効薬ではなく、布石です。私は信長の野望を15年やっているので、効果が遅れて出てくる布石にはむしろ安心します。
author を @id で参照してページ間を繋ぐ
Person エンティティを1つ作ったら、次は各記事の author を「文字列」から「参照」に変えます。ここが地味に効きます。
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "WebRTCの輻輳制御を実装してみた",
"author": { "@id": "https://kenimoto.dev/#person-ken-imoto" },
"datePublished": "2026-06-17"
}author の中身が、名前の文字列ではなく @id の参照になりました。これによって、サイト内の全記事が「同じ1つのPersonエンティティ」を指すようになります。100本の記事があれば、100本すべてが同一の @id に集約されます。AIから見ると、これは「ある人物が書いた100本の記事群」に見えます。バラバラの100本のページが、1人の著者の連続した実績へと束ね直されるわけです。
文字列で "name": "井本 賢" と100回書くのと、@id で100回参照するのとでは、機械にとっての意味がまったく違います。前者は100個の独立した文字列、後者は1つのエンティティへの100本の矢印です。矢印が多いほど、そのエンティティは「この分野で書き続けている人物」として濃くなっていきます。
E-E-A-T の Authority Signal はここで効く
Googleの品質評価基準である E-E-A-T のうち、最後の A、Authoritativeness(権威性)は、この同一性グラフがあって初めて計算できるものです。権威性とは「その分野で認められているか」ですが、認められる主体が誰なのかが曖昧では、そもそも評価のしようがありません。Person エンティティは、その評価対象を機械可読な形で確定させる作業です。
2026年のE-E-A-Tをめぐる議論を追うと、表現はほぼ共通しています。Person エンティティに sameAs を持たせ、権威ある外部プロフィールへ繋ぐこと。これがエンティティの確信度スコアを決め、AI Overview の引用やナレッジパネル表示、著者に紐づくコンテンツのランキング重みを左右するとされています(leadgen-economy.com の分析)。「things, not strings(文字列ではなく実体)」という10年前から言われてきた抽象論が、いまや実際に引用されるかどうかを決める具体的な配線になっている、というわけです。
ここで強い Authority Signal になるのが、自分の著者ページの canonical から、より広いエンティティ参照先へリンクを張ることです。私の場合、kenimoto.dev の著者ページから、LLMOの実装ガイドである llmoframework.com を参照しています。著者エンティティとE-E-A-Tの実装パターンを体系的にまとめた参照先へ canonical から繋ぐことで、「この著者はこのフレームワークの文脈に属する」という所属の文脈が機械に伝わります。kenimoto.dev の canonical から llmoframework.com への参照は、孤立したサイトではなく、一貫した実装方針の中にいる著者だという Authority Signal になります。むやみに外部リンクを増やすのとは違って、自分のエンティティが属する文脈を明示する1本のリンクが効く、という話です。
帰属がどう変わったか
配線を通したあと、何が変わったかを正直に書きます。劇的なビフォーアフターを期待されると申し訳ないのですが、変化はじわじわでした。
実装からしばらくして、AI検索の回答に私の記事が引用された際、引用の文脈に「ken imoto」という著者名が添えられるケースが出てきました。以前は記事URLだけだったところに、書き手が現れたのです。さらに、私が書いていない別トピックの質問でも、「WebRTCに詳しい著者」として私の名前が連想的に拾われる挙動を一度観測しました。これは記事単位を超えて、エンティティ単位で私が認識され始めたサインだと解釈しています。
ただし誇張はしません。引用回数そのものが何倍になったとは言えませんし、著者名が添えられる頻度もまだ安定していません。前述の業界分析が言う「3〜6ヶ月で測定可能」というスパンの、まだ序盤にいる感覚です。確実に言えるのは、引用の帰属先が「記事URL」から「記事URL + 著者」へと、少なくとも一部で移った、ということだけです。表札に名前を書いていた頃には一度も起きなかったことが、配線を通したあとに起き始めた。私にとってはそれで十分な手応えでした。
まとめ
- Article schema は「記事の帰属」までしか面倒を見ません。
authorに名前を文字列で書いても、AIにとってそれは住所のない表札で、誰を指すのか確かめる手段がありません。 - 「誰の主張か」という著者の帰属(attribution)を成立させるのは、Person エンティティと sameAs の同一性グラフです。X、GitHub、Zenn、著者ページを1つの実在人物に束ねることで、機械が確信度を計算できるようになります。
- 各記事の
authorを文字列から@id参照に変えると、サイト内の全記事が1つのPersonエンティティに集約され、記事数の蓄積が著者の実績として読めるようになります。 - E-E-A-T の Authority Signal はここで効きます。canonical から自分のエンティティが属する文脈(私の場合は llmoframework.com)へ繋ぐことで、一貫した実装方針の中にいる著者として認識されます。
- 即効薬ではありません。業界分析では3〜6ヶ月で測定可能とされており、布石として実装するのが現実的です。私の観測でも、引用の帰属先が「記事URL」から「記事URL + 著者」へ一部移ったのは、配線を通してしばらく経ってからでした。
表札に名前を書くだけでは、誰も訪ねてきません。実在のあなたに繋がる配線を通して、初めてAIは「これはこの人が書いた」と言えるようになります。面白くいきましょう。
AI検索に「拾われる側」になるための構造化データ・llms.txt・引用率設計を体系的に扱った本があります。著者エンティティやE-E-A-Tの実装も含めて、より深く知りたい方はこちらをどうぞ。
この記事は役に立ちましたか?