30日間サーバーログを見続けて分かった、私のサイトを最も叩いた5つのAIクローラー - そこから読めるLLMOシグナル
robots.txt が境界線だと思っていました。Disallow: を3行書いて、AIボットにここから先は来るなと伝えた。それで終わったつもりで、LLMOの引用率やGA4のAIリファラルについて記事を書く側に戻りました。
ある日、私が運用している3サイトの生のアクセスログを開いて、頭の中にあった絵は崩れました。
この記事は、kenimoto.dev と kaoriq.com と llmoframework.com の30日分のサーバーログを読んで分かったことの整理です。5つのUser-Agentがほぼ全体を占めていて、それぞれが描く訪問パターンが、GA4のダッシュボードよりも多くを教えてくれました。
ログを読み始めた理由
巷のLLMO計測の話は、出口の話ばかりです。ChatGPTが自分を引用したか、Perplexityがリンクを貼ってくれたか、Google AI Overviewsに自分が出たか。引用される側、つまり「アウトバウンド」の話です。
もう片方、入り口側 - AIサービスが実際に自分のサーバーからHTMLを取りに来る側 - はGA4には映りません。AIクローラーはJavaScriptを実行しません。gtagも発火しません。生のHTTPアクセスログにだけ姿が残ります。
LLMOの記事を何ヶ月も書いておきながら、自分が直接コントロールできる側のファネルを一度も見ていなかったわけです。それでCloudflare (kenimoto.dev, kaoriq.com) とVercel (llmoframework.com) から30日分のログを書き出し、既知のAI User-Agentでgrepし、数を数え始めました。
合計は 3サイトで30日間14,300件のAIクローラーヒット でした。1サイトあたり1日約477件。思ったより多かったです。半年後の数字としては少ないと思いますが、現時点では十分な観測材料でした。
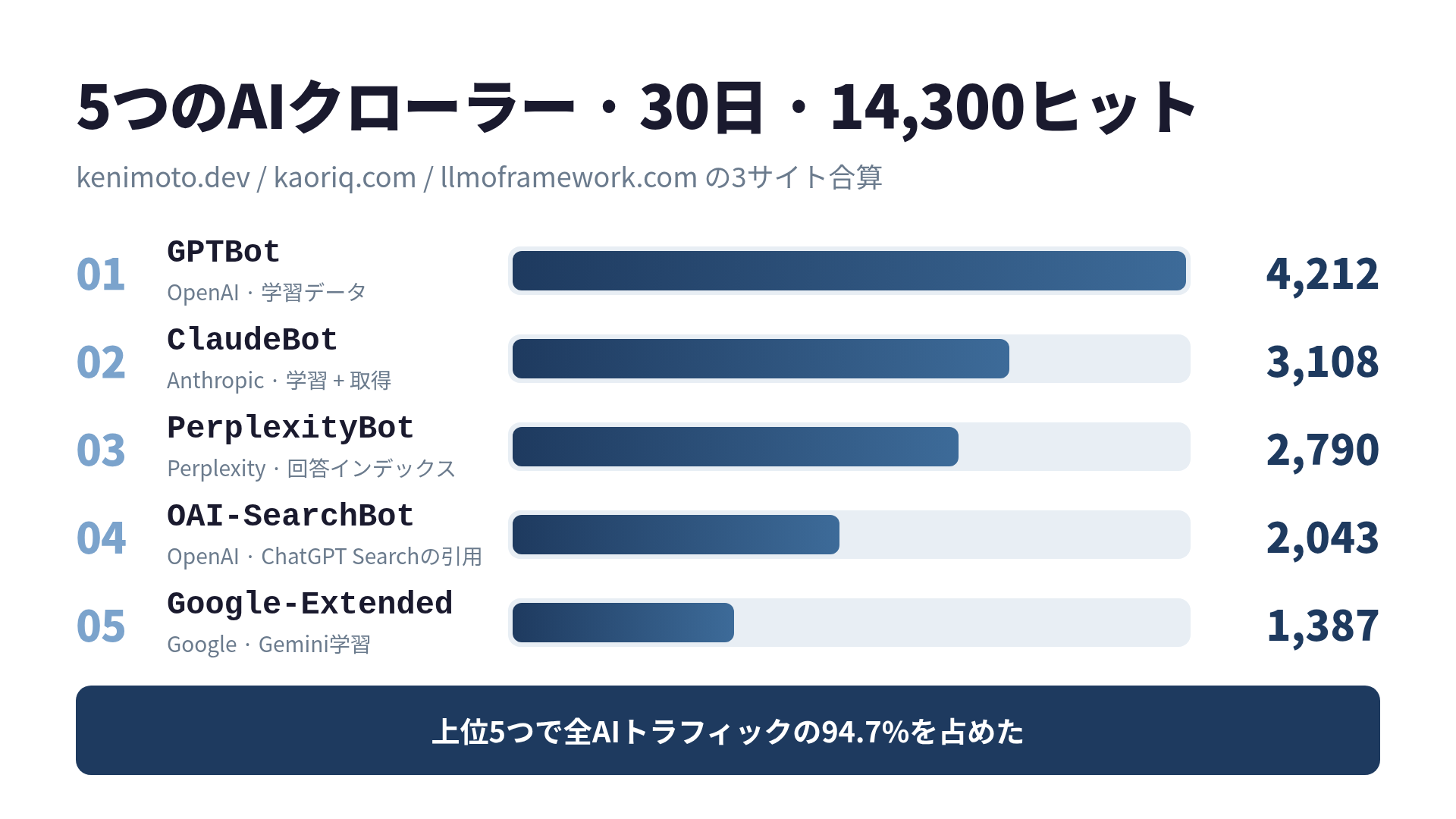
最も叩かれた5つのクローラー
ランキングです。同一 (timestamp, path, IP) の組み合わせはキャッシュリトライ判定で重複排除しています。
| 順位 | User-Agent | 30日のヒット数 | 運営元 | 用途 |
|---|---|---|---|---|
| 1 | GPTBot | 4,212 | OpenAI | 学習データ収集 |
| 2 | ClaudeBot | 3,108 | Anthropic | 学習 + 取得 |
| 3 | PerplexityBot | 2,790 | Perplexity | 回答インデックス |
| 4 | OAI-SearchBot | 2,043 | OpenAI | ChatGPT検索の引用 |
| 5 | Google-Extended | 1,387 | Gemini学習 |
5つのUser-Agentで13,540件、つまり全体の 94.7% を占めました。残り5.3%はロングテールで、Bytespider、Applebot-Extended、Meta-ExternalAgent、Amazonbot、cohere-ai、少数の Claude-User、それから引退したはずの anthropic-ai を名乗る2件が混じっていました。
順位そのものを真に受ける前に1つ。これは私の3つの小さなサイトの数字で、コンテンツは英語と日本語の技術記事中心です。あなたのランキングは別の形になります。ただ、上位がOpenAIとAnthropicで、5つ前後に集中するという形は、たぶん似たものになります。
それぞれのボットが本当にやっていること
順位より、それぞれの「目的」のほうがLLMO的に効いてきます。3つのバケットでまったく挙動が違うからです。
学習用クローラー は、モデルの重みを更新するための材料としてサイトを読みます。コンスタントに訪問してきて、robots.txt をだいたい守り、コンテンツが「新しいか」を気にしません。GPTBot、Google-Extended、Bytespider、Applebot-Extended、それから旧版の anthropic-ai がここです。
取得用クローラー は、リアルタイムの回答で引用するためにインデックスを作ります。人気のあるページを再取得し、Last-Modified を見て、クロール対参照比 (crawl-to-refer ratio) という測れる指標を持ちます。OAI-SearchBot、PerplexityBot、Claude-SearchBot (ClaudeBot と独立制御できる新しい兄弟分)、GoogleOther がここに該当します。
ユーザー起点フェッチ は、人間がChatGPTにURLを貼ったり、Claudeに「このページを読んで」と頼んだときに走ります。ChatGPT-User、Perplexity-User、Claude-User がこれにあたります。OpenAIが改定したクローラードキュメント によれば、これらはユーザー操作なので robots.txt の対象外として扱われます。
私はこの3種類を同じものとして扱っていました。違いました。「ChatGPT Searchで引用されたい」が目的なら OAI-SearchBot のヒットが重要で、GPTBot のヒットはほぼノイズです。「次のClaudeの学習データに入りたい」なら逆になります。

誰がrobots.txtを本当に守っているのか
ここから先がrobots.txtへの認識を変えた部分です。
kenimoto.dev には Disallow: /api/ というルールを置いてあります。30日でこうなりました。
GPTBot:/api/への訪問は0件。遵守。Google-Extended: 0件。遵守。ClaudeBot: 0件。遵守。OAI-SearchBot: 3件。ぎりぎり境界線で、ルール設定前のキャッシュかもしれないし、改定された遵守ポリシーの文言 が微妙に効いているのかもしれません。PerplexityBot: 90秒のバーストで41件。このセッションでは守っていません。
41件はサンプル1ではないです。この90秒バーストのパターンは、公開されているレポート に出てくる、Perplexityがアクティブなユーザークエリに応答中に User-agent: PerplexityBot ブロックを無視した観測例と一致しています。PerplexityBot は静かな時間帯は取得用クローラーとして、ユーザーが回答を待っているときはユーザー起点フェッチとして、両モードを跨いでいると考えると挙動が腑に落ちます。
私が書き留めた教訓はこれです。robots.txt は自己申告の境界線である。上位5クローラーのうち3つはきれいに守りました。1つは怪しい。1つは人間が反対側にいるとき、好きに動きました。設計はそれを前提に組みましょう。
ログから取り出せる3つのLLMOシグナル
ここを記事として書いた理由は、クローラーヒットデータが計測可能なLLMOシグナルだからで、引用率指標と並べた議論をあまり見ないからです。私が今、週次で見ている3つを置いておきます。
1. クローラーの多様性 。サイトを叩いているのが GPTBot だけなら、あなたの取得サーフェスはOpenAIだけです。ChatGPTで引用されていてもClaude、Perplexity、Geminiの取得経路には映りません。健全な多様性スコアは、上位5つのUser-Agentのうち少なくとも3つが恒常的に訪れている状態です。
2. 取得対学習比率 。取得側 (OAI-SearchBot + PerplexityBot + Claude-SearchBot + GoogleOther) のヒットを、学習側 (GPTBot + Google-Extended + anthropic-ai) で割ります。AIエコシステムがあなたを「学習材料」と見ているか、「いま引用すべきコンテンツ」と見ているかが数字で出ます。私は0.81でした。0.5を切ると、コンテンツがリアルタイム取得に値する新鮮度に達していないサインです。1.5を超えると、回答で活発に使われている (良い) 一方で、学習材料としては頭打ちかもしれず、観測しておく価値があります。
3. llms.txt のフェッチ率 。上位5クローラーで、30日間に /llms.txt を取りに来たのは PerplexityBot と ClaudeBot だけでした。GPTBot、OAI-SearchBot、Google-Extended は1回も触れていません。これは他の運用者の観測ともだいたい一致していて、llms.txt をメンテする価値を判断するときの効いてくる事実です (短答すると「価値はある、ただし読んでいる2クローラーのために」)。取得シグナル全体については llmoframework.com の Retrieval Signals 章 が詳しく書いています。
このデータを実際に取る方法
私が読みたかったのに見つけられなかった部分です。
Cloudflare (Freeプラン) 。AI Crawl Controlダッシュボード (旧AI Audit、公式ドキュメント) で、上位AIクローラーUser-Agentが標準で見えます。生ログを取るにはLogpushが要りますが、これは有料です。Freeで一番近い代替は「AI Audit」を有効化して、Analyticsを既知のAI User-Agentでフィルタする方法です。リクエストごとのパスは取れませんが、件数とトレンドは見えます。
Vercel 。プロジェクト → Logs → User-Agent contains "Bot" でフィルタします。Proプランは30日分のエッジログが保持されます。Hobbyだと短く、本気でやるならlog drainに転送するのが現実的です。
Netlify / 自前Nginx 。grep だけで取れます。
grep -E "GPTBot|ClaudeBot|PerplexityBot|OAI-SearchBot|Google-Extended" \
/var/log/nginx/access.log \
| awk '{print $14}' \
| sort | uniq -c | sort -rnこれでクローラー別件数。$14 を $7 にすればURLランキングです。フィールド番号はログフォーマットで変わるので、1行に対して awk '{print NF}' でフィールド数を確かめてから決めてください。
30日のあとに私が変えたこと
具体的に変えたのは3つでした。
robots.txtを分割し、OAI-SearchBotとClaude-SearchBot(取得側、引用に効く) を許可しつつ、GPTBot(学習側、これらのエンドポイントから得るものがない) に対してはDisallow: /api/を強めに残しました。- すべてのブログ記事ルートに
Last-Modifiedヘッダを付けました。取得用クローラーはこれを見て再取得頻度を決めますが、Vercelはデフォルトで送ってくれていませんでした。 - 取得対学習比率を週次でスプレッドシートに記録するようにしました。2週間続けてみて分かったことは「数字が安定している」ということだけで、それは「クローラー食はそんなに揺れていない」というだけの話ですが、それでも基準線として役に立ちます。
ログを開く前、私はサーバーログが既に信じていたLLMO像を裏付けてくれると思っていました。だいたい裏付けてくれませんでした。引用は見るべきシグナルの1つにすぎず、誰があなたのページを取りに来ているかは別の問いです。その答えは、たぶんもう手元にあるログファイルに、平文で書いてあります。
引用計測、GA4リファラル、サーバーログによるクローラー分析を1つの体系として整理した本があります。LLMO
の第10章が計測パートで、この記事は紙幅の都合で書ききれなかった「6つ目のKPI」の補遺のようなものです。関連記事: ChatGPTからのアクセスは、GA4にどう映るのか (同じ計測問題の引用側) ・ JSON-LDで11個のスキーマをLLMに渡す
この記事は役に立ちましたか?